OpenAI AgentKit turns agent ideas into production reality
OpenAI’s AgentKit unifies Agent Builder, ChatKit, a Connector Registry, and upgraded Evals with reinforcement fine tuning to shrink agent deployment from weeks to days while adding governance, visibility, and control.
Breaking: AgentKit makes agents a production story, not a prototype
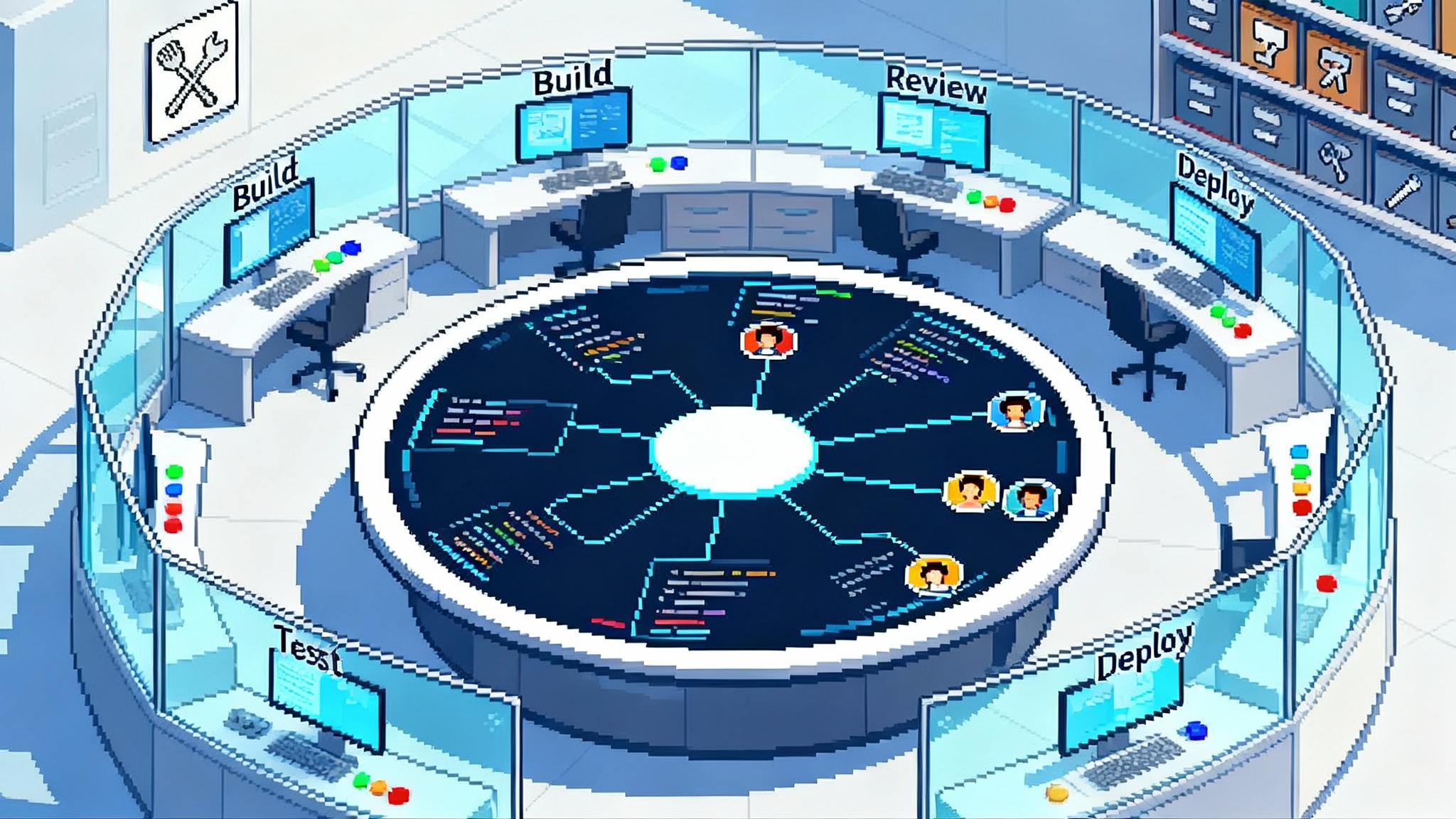
On October 6, 2025, OpenAI introduced AgentKit, a first‑party toolkit for building, shipping, and governing AI agents. The launch brings four pillars under one roof: Agent Builder for visual design and versioning, ChatKit for embeddable chat interfaces, a Connector Registry for enterprise data and tool access, and a new wave of Evals plus reinforcement fine tuning for measurement and optimization. The stated goal is simple and ambitious: take agents from slideware to shipping code with far less friction. For official details, see the OpenAI AgentKit launch.
If you have been piloting agents with a tangle of orchestration scripts, one‑off connectors, and ad hoc evaluation notebooks, you have felt the pain. Weeks disappear into wiring and governance instead of outcomes. AgentKit reframes that workflow: design on a canvas, plug in approved connectors, ship a standardized chat experience, measure with trace‑level evals, and push performance with reinforcement fine tuning. The result is not only speed. It is standardization, which is what enterprise teams need to run agents at scale.
The one‑sentence thesis
AgentKit compresses time to production by moving the agent lifecycle into a single, governed platform where the core steps are standardized and observable: design, connect, embed, evaluate, and optimize.
Why this is an inflection point
Standardization is the difference between a cool demo and a durable program. In software history, many inflection points arrived when scattered practices congealed into shared primitives: package managers in web development, container images in cloud, continuous integration in delivery. Agents have lacked those primitives. AgentKit offers them in a form that legal, security, and engineering can agree on.
Here is the practical shift:
- A consistent design surface: Agent Builder lets teams sketch multi‑step workflows as nodes and edges, commit versions, and review diffs. That means legal and product managers can sign off on the same artifact engineering ships.
- A shared interface pattern: ChatKit gives product teams a ready‑made and customizable chat front end that handles streaming, threading, and tool call disclosure. No more reinventing the chat wheel.
- A central authority on data and tools: the Connector Registry provides a single admin panel where owners approve which systems an agent can reach, with organization‑wide visibility and revocation.
- A measurement backbone: Evals move from sporadic prompts in a notebook to datasets, trace grading, and automated prompt iteration. Reliability becomes a tracked metric instead of wishful thinking.
- A performance ratchet: reinforcement fine tuning lets you teach models to use your tools at the right time and optimize toward custom graders, so agents improve instead of plateau.
When these pieces snap together, cycle time drops from weeks to days because less energy is lost to glue code and approval loops.
What exactly launched
OpenAI positioned AgentKit as a complete developer and enterprise toolkit. The most relevant details for planning roadmaps:
- Agent Builder: a visual canvas for composing agent logic, connecting tools, and configuring guardrails. Includes preview runs, inline eval configuration, and versioning.
- ChatKit: a toolkit for embedding chat‑based agent experiences into apps and sites. Handles streaming responses, thread state, and in‑chat actions with your branding.
- Connector Registry: a central place to manage data sources and tools across OpenAI products, including common third‑party services. Admins can grant, scope, and revoke access from one place.
- Evals for agents: datasets, automated graders, prompt optimization, and trace‑level analysis, with support for evaluating third‑party models.
- Reinforcement fine tuning: also called RFT, a training path that optimizes agents for your objectives, including better tool selection and custom graders.
Availability matters. As of launch, OpenAI states that ChatKit and the new Evals capabilities are generally available. Agent Builder is in beta. Connector Registry is rolling out in beta to organizations with the Global Admin console. RFT is generally available on a reasoning model and in private beta for the next generation model. This staggered rollout is typical for platform features that touch governance.
For teams already investing in agent operations, AgentKit lands alongside a broader movement toward operational maturity. You can see similar instincts in our look at AWS AgentCore enterprise runtime and how workflow‑level primitives reduce custom glue code.
From weeks to days: the before and after
Think of an agent that investigates billing disputes, gathers evidence from your CRM, invoicing system, and chat logs, and drafts a customer‑ready explanation. Here is how the build process used to look.
Before AgentKit:
- Engineering coded orchestration for tool calls and retries. Design lived in a whiteboard photo and a Notion page, which quickly diverged from the code.
- A front‑end team spent one to two weeks crafting a chat experience with streaming, copy to clipboard, footnotes, and security reviews.
- Data engineering wrote one‑off connectors for internal systems and chased access approvals across teams.
- Evaluation was a spreadsheet of tricky cases and a partial notebook. Most of the trace was invisible.
- Performance improvements involved prompt tweaking, gut feel, and a few human annotations.
After AgentKit:
- Product and engineering map the workflow on Agent Builder. They connect approved tools from the Connector Registry. The canvas becomes the source of truth with versioning.
- They embed ChatKit in the internal dashboard and roll out to a pilot group in a day. The interface handles streaming and threads without bespoke code.
- Security points to the Registry configuration. Access is scoped and revocable without a code change.
- Evals datasets are created from past cases. Trace grading pinpoints where the agent hesitates or calls a tool too often. Prompt optimizer suggests revisions grounded in annotations.
- RFT teaches the agent to call the right tool at the right time. Custom graders reflect what your finance team counts as a correct resolution.
The calendar math changes. A pilot that once soaked up two to three sprints now stands up in a matter of days because so many cross‑cutting concerns are pre‑solved.
Deep dive on the four pillars
1) Agent Builder: a living spec everyone can read
Agent Builder is best understood as an executable diagram. It makes system design visible, but it is not just a picture. You can run preview traces, tweak parameters, attach guardrails, and commit versions. That helps avoid the classic drift where code and intent part ways. In regulated settings, that living spec becomes the artifact for audits and reviews.
Useful behaviors to expect:
- Templates for common multi‑agent patterns such as retrievers, orchestrators, graders, and tool routers.
- Inline eval hooks so each change can be tested on a known dataset without leaving the canvas.
- Version history that maps to deployment gates, so you know which version is serving traffic.
The Builder also opens a shared language across functions. PMs can talk in terms of steps and guardrails. Legal can sign off on explicit data flows. Security can compare intended access with the Registry configuration. Engineers finally ship the thing that everyone already agreed to, not a best guess.
2) ChatKit: the last mile without the last‑mile tax
Chat is the default interaction model for agents because it blends natural language with structured actions. It is also surprisingly tedious to implement well. The hard parts are stateful: streaming text, tool call visibility, interruptibility, and authentication. ChatKit abstracts those tasks so your front‑end team can focus on product choices like message formatting and brand. Many teams quietly admit that chat UIs are time sinks. Every custom version adds future maintenance, new security reviews, and inconsistent patterns.
In earlier analysis of code assistants, we saw how a central interface and policy layer can unlock predictability. That same logic shows up when you compare AgentKit’s ChatKit to the control centers others are building, like the unified visibility we covered in GitHub Agent HQ.
3) Connector Registry: one switchboard instead of ten email threads
Enterprises need a single place to assert who can reach what. The Connector Registry acts like a switchboard where admins approve connectors to cloud drives, collaboration tools, data warehouses, and internal services, then scope access by workspace or organization. The presence of a central panel changes incentives. Teams no longer need to ship glue code just to connect. They request access, it is granted or denied with a record, and everything remains visible for later revocation. That lowers the blast radius of mistakes and speeds compliance checklists.
Expect the Registry to become the front door for tool use policies. Over time this could include conditional access, per‑connector guardrails, and usage analytics that answer questions like which agent is touching which datasets. If that evolution lands, the discipline of agent ops will start to look a lot like platform engineering with clearer boundaries and fewer one‑off exceptions.
4) Evals and reinforcement fine tuning: the performance flywheel
Evals for agents do two important things. First, they make tests a first‑class object: you build datasets, annotate failure modes, and run trace grading to see where the agent went off track. Second, they link directly to improvement loops. Prompt optimizer uses grader feedback and human annotations to propose changes. And if you need more than prompt surgery, reinforcement fine tuning kicks in.
Reinforcement fine tuning is how you teach a model to act more like your best operator over time. Imagine coaching a new analyst. You do not only correct the final answers. You reward good choices at each step: checking the contract first, selecting the correct internal system, asking a clarifying question. RFT captures that idea in code. You define what good looks like through custom graders, run many episodes, and the model learns the policy that maximizes those rewards. For planning and cost control, consult the OpenAI RFT billing guide.
Two tactical notes for practitioners:
- Start with Evals datasets that mirror your top failure modes. RFT works best when it has precise signals, and those signals come from clear graders and representative traces.
- Teach tool timing. Many agent failures are not hallucinations but poor timing and selection of tools. RFT’s ability to train tool calls directly addresses this.
Safer tool use is not a bonus feature, it is the main event
Agent safety is often framed as content moderation. In reality, the riskiest failures are usually tool misuse and overreach, like pulling the wrong customer data or hitting a production endpoint without guardrails. AgentKit brings several protections closer to default: guardrails that screen for personally identifiable information and jailbreak attempts, a Registry that scopes access, and Evals that catch regressions before they impact users.
Think of safety like circuit breakers in a house. You still need good wiring. Circuit breakers make sure a single bad appliance does not burn the place down. In agent ops, that means making default tool access narrow, logging everything, and promoting changes only after a representative eval pass.
Interoperable connectors and the 2026 reality
The near future of enterprise agents is polyglot. You will use multiple models, attach them to many business systems, and embed them across web, mobile, and internal tools. A Registry that spans ChatGPT and the API and centralizes common connectors is a step toward interoperability. It reduces duplicated work and brings tool governance to where agents live. If standardized connectors mature into a marketplace with predictable security and upgrade paths, 2026 looks less like a zoo of bespoke adapters and more like an ecosystem of reliable components.
This direction rhymes with the modular philosophy we discussed in Agent Bricks production pipeline, where repeatable components replace bespoke wiring so teams can spend time on differentiated logic.
Early signals from the field
OpenAI highlights customer results that, while vendor‑reported, map to what many teams are seeing:
- Iteration cycles cut by roughly 70 percent when a shared canvas replaces scattered documents.
- Evaluation timelines reduced by around 40 percent with dedicated datasets and graders.
- Two weeks of interface work avoided by embedding ChatKit instead of building from scratch.
- Accuracy improvements near 30 percent after adopting structured Evals.
Case studies span support, sales, internal knowledge assistants, and research agents. The pattern is consistent: lift and speed come from removing glue work and measuring the right things early.
What to do next if you lead an agent initiative
- Map one production‑adjacent workflow onto Agent Builder. Choose a process with clear correctness criteria and tool calls, like billing disputes or contract redlining. Ship a small version in a week.
- Stand up Evals on day one. Collect 50 to 200 representative cases, write graders for the two failure modes that cost you the most, and start measuring before anyone outside the team touches the agent.
- Limit the connector surface. Approve only the few tools required for your first workflow, grant read access where possible, and log every call. Expand only when evals show real value.
- Use ChatKit to get real users in the loop. Feedback from actual users inside your product is worth more than another week of prompts. Keep the interface minimal and instrumented.
- Consider RFT only after prompt and tooling fixes plateau. It is powerful and it is not free. Make sure graders encode your real objective and that you can afford the training runs.
These steps turn AgentKit from a press release into a working pipeline that can survive an audit and a holiday traffic spike.
Risks and realities worth noting
- Platform lock‑in is real. Standardization helps ship faster, but it nests your workflows in a specific platform. Mitigate that by exporting evaluation datasets and keeping business logic modular.
- RFT is a ratchet, not a magic wand. It will not fix a missing system of record or a vague policy. Invest in clear graders and data hygiene.
- Connectors create attack surface. The Registry centralizes control, but you still need least privilege, per‑connector review, and usage alerts.
- Measurement is culture. Evals only matter if teams treat red results as a stop sign, not a suggestion. Promote versions only after they pass.
The bigger picture: toward agent ops as a discipline
Agent ops is emerging as a recognizable function that blends product, security, data engineering, and machine learning operations. It needs common tools, common reviews, and common metrics. With AgentKit, OpenAI is arguing for a default stack that a Global Admin can understand, a developer can extend, and a compliance officer can sign. The prize is not just faster shipping. It is a way to onboard new teams, enforce safety consistently, and improve agent behavior like any other production system.
This is also why cross‑vendor fluency matters. Your program will likely combine platform‑native controls with peripheral tools and domain‑specific plugins. Lessons from the broader ecosystem, including our coverage of AWS AgentCore enterprise runtime and GitHub Agent HQ, suggest the winners will choose a standard, measure relentlessly, and only customize where it truly counts.
The bottom line
AgentKit does not invent new ideas so much as it arranges them where enterprises can use them. Visual design as source of truth, embeddable chat as a commodity, connectors as governed infrastructure, evals as the heartbeat, and reinforcement fine tuning as the ratchet that turns good into great. Tie those together and time to production stops being the bottleneck. If the next year looks like the last decade of software, the teams that adopt a standard and build a culture of measurement will move faster and break less. AgentKit gives them a head start.