AgentKit moves AI agents from demo to deployable platform
OpenAI’s AgentKit bundles Agent Builder, ChatKit, Evals, a governed Connector Registry, Guardrails, and reinforcement fine-tuning to move teams from demo to deployment. This review adds a 30-60-90 plan, metrics, and an architecture you can ship.

Breaking: OpenAI AgentKit is the missing full stack for agents
On October 6, 2025, OpenAI introduced a cohesive platform for building and running agents. In the official product post, OpenAI introduced AgentKit and packaged four pillars into one toolkit: Agent Builder, ChatKit, an expanded Evals suite, and a Connector Registry. The goal is to replace the fragile stitchwork that sits between a flashy demo and a durable production system.
AgentKit’s short take is simple. It gives teams a visual way to design multi-agent workflows, a drop-in chat experience that feels native, a disciplined path to measure and improve performance, and a governed place to connect data and tools. It is not one agent. It is scaffolding that lets many agents work together inside the rules of your product and organization.
Why AgentKit matters now
For the last two years, most agent demos looked magical on a laptop and brittle in production. Familiar failure modes repeated across teams:
- No versioned workflow or change history.
- Prompts scattered across code, docs, and dashboards with no single source of truth.
- Homegrown connectors that broke on permission changes or expired tokens.
- Improvised chat interfaces that could not handle streaming, retries, or long threads.
- Evaluation spreadsheets that no one trusted and that no one had time to maintain.
AgentKit targets those seams. It centralizes the workflow, the user interface, the evaluation loop, and the connection to tools and data so you can iterate with confidence. If your goal is not just speed but institutional memory, that matters. A workflow you can re-run, inspect, audit, and improve becomes an asset rather than a clever one-off.
What is in the box
Here is a concise tour of the shipped components and their current status.
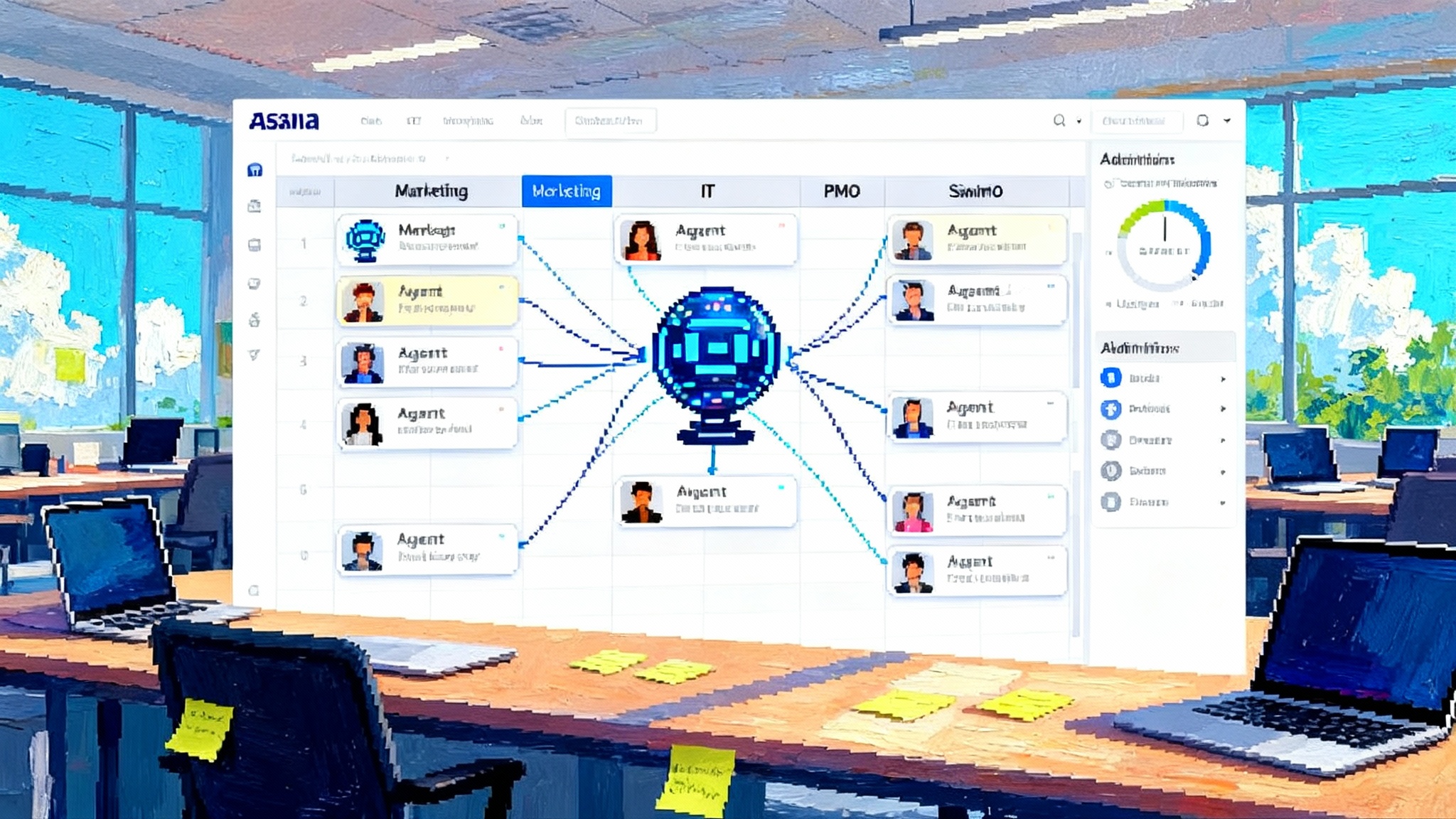
- Agent Builder. A visual canvas for composing multi-agent logic, attaching tools, configuring guardrails, and running preview tests. It supports full versioning so rollback is routine, not a fire drill. Availability: beta per the launch post.
- Agents SDK and Responses API. Code-first building blocks that power the same workflows for teams who prefer code over canvas. The SDKs allow type-safe tool calls and clean orchestration without prompt spaghetti.
- ChatKit. An embeddable, brandable chat that handles streaming, threads, tool invocation, retries, file uploads, and customizable prompts. Availability: generally available at launch.
- Evals. Datasets for test cases, automated graders, trace grading that follows an end-to-end run, and prompt optimization based on human and automated feedback. Crucially, it evaluates third party models so you can run head-to-head comparisons without switching tooling. Availability: new capabilities generally available at launch.
- Connector Registry. A centralized admin-governed catalog that moves connectors from one-off glue code to a managed inventory. It includes prebuilt connectors for Dropbox, Google Drive, Microsoft SharePoint, Microsoft Teams, and support for Model Context Protocol providers. Availability: beginning beta rollout tied to the Global Admin Console requirement.
- Guardrails. An open safety layer that can flag or mask sensitive data, detect jailbreak tactics, and apply policy consistently across agents. You can deploy Guardrails as part of Agent Builder or in code with language libraries.
- Reinforcement fine-tuning. Reinforcement fine-tuning is generally available on OpenAI’s o4-mini and in private beta for GPT-5, with features like custom tool call training and custom graders to push agent performance on your domain.
For a single-page summary of how these pieces fit together, see OpenAI’s Agent platform overview.
From demo to deployable: a 30-60-90 day playbook
You can ship a serious multi-agent workflow in a quarter if you treat agents like a product.
Days 1 to 30: prove value with a narrow slice
- Pick one job-to-be-done that already has tickets and measurable outcomes. Good candidates include support triage, sales prospect research, policy Q and A, or internal knowledge search.
- Write service level objectives instead of vibes. For support triage, define targets such as 80 percent correct routing on first pass, median response under three seconds for common queries, and a cost cap per conversation.
- Map tools and data before writing prompts. Use the Connector Registry to enable only what you need. Start read-only. Add write scopes later with explicit review.
- Build a minimal workflow in Agent Builder. Keep it simple: one planner agent, one tool caller for search or retrieval, and one responder. Add base Guardrails to block sensitive outputs and unsafe actions.
- Embed with ChatKit in a staging environment. Resist the urge to rebuild chat. You will need streaming, retries, partial responses, and thread state from day one. ChatKit gives you those primitives.
- Instrument everything. Log prompt versions, tool calls, latency, token usage per step, and user outcomes. Decide what you retain for audit and improvement.
Days 31 to 60: harden and scale the workflow
- Create a realistic eval dataset. Start with 100 examples from your own logs. Label expected outcomes and include tricky edge cases that reflect real user behavior.
- Turn on trace grading in Evals. Move beyond pass or fail. Identify whether the planner chose the wrong tool, the retriever returned stale data, or the responder hallucinated a policy.
- Introduce automated prompt optimization. Use graders and human annotations to propose prompt edits. Compare A versus B runs in Evals until you cross your SLO thresholds.
- Add a fall-through path. When confidence is low or costs spike, hand back to a human, request clarification, or switch to a cheaper model for low-stakes steps.
- Run a red team drill. Try jailbreaks, prompt injection, and data exfiltration attempts. Confirm Guardrails and connector permissions behave as designed. Document fixes and retest.
Days 61 to 90: productionize and expand
- Roll out to a controlled cohort with a change log tied to Agent Builder versions. Every change should have an expected delta in accuracy, latency, or cost.
- Automate deployment gates. New versions must pass your eval suite with equal or better scores. Fail fast and roll back quickly when needed.
- Extend to a second agent. In sales research, add an enrichment agent that cross-checks contact data and a routing agent that prioritizes accounts. Use planner, worker, reviewer patterns with explicit roles.
- Identify one write action. Examples include creating a support ticket, sending a draft email, or updating a CRM field. Require human confirmation until your evals prove reliability.
- Establish owner teams. Assign a product owner, an evaluation owner, and an on-call engineer. Agents are software. Treat them like a service.
Architecture blueprint you can copy
Think in layers instead of a ball of prompts.
- Interaction. ChatKit inside your web or native app. It manages streaming, thread state, uploads, and tool call events.
- Orchestration. Agent Builder or the Agents SDK coordinates planner and worker agents, tools, and Guardrails. Keep versions aligned across staging and production.
- Tooling. A set of approved functions and connectors with minimum scopes. Wrap dangerous actions with confirmation prompts, rate limits, and audit logs.
- Memory and context. Choose the smallest context that works. Cache system prompts and few-shot examples. Use retrieval only where needed and track hit rate.
- Observability. Collect structured traces for every step. Emit metrics for accuracy, latency, cost, and tool errors. Tie traces back to Agent Builder versions and eval suite runs.
- Safety. Guardrails at input and output, plus policy checks before tool execution. Log policy hits and operator overrides for later review.
If you want a comparative view of how other vendors frame the agent operating system, see how Google positions Workspace in Gemini Enterprise turns Workspace into a multi-agent OS and how Salesforce makes CRM the control plane in Agentforce 360 makes CRM the control plane for AI agents.
Numbers that matter
Reliability is a metric practice, not a promise. Use these pragmatic starting points and tune them per use case.
- Accuracy. Target 85 to 90 percent on your eval dataset before wide release. Track separate scores for planning, retrieval, and final answer.
- Latency. Aim for a median under two seconds for knowledge responses and under five seconds for tool-heavy workflows. Alert on the 95th percentile.
- Cost. Set a ceiling per conversation and per successful action. Alert when the average cost per success rises for three straight days.
- Deflection rate. For support scenarios, measure what percentage of conversations resolve without a human. Tie incentives to customer satisfaction, not deflection alone.
- Safety. Zero tolerance for policy violations in production. Track near misses from Guardrails to spot prompt or tool drift before it becomes visible to users.
Case studies to learn from
OpenAI’s launch materials highlight teams that moved from experiments to outcomes. A financial services firm cut iteration cycles by roughly 70 percent after switching to Agent Builder because product, legal, and engineering could finally work in one interface. A consumer software company embedded ChatKit and saved two weeks of front end work while shipping a developer support agent in under an hour. An investment firm used the new Evals features to increase accuracy around 30 percent on a multi-agent due diligence workflow. The point is not that every team gets the same numbers. It is that coordination cost drops and results become measurable.
If you want a developer-fast comparison point for engineering workflows, read how GitHub-centric teams think about mission control in Agent HQ turns GitHub into mission control for coding agents.
Guardrails and governance are part of the product
Every year the risk conversation moves earlier in the project. AgentKit bakes governance into how you connect tools and data from day one. The Connector Registry lives behind the Global Admin Console so the same people who manage identity and single sign-on also control which data sources are available to which teams. That is how you avoid shadow connectors and inconsistent scopes.
Guardrails add a safety layer that does three critical jobs. First, it keeps regulated data in bounds by masking or blocking sensitive fields. Second, it detects jailbreak tactics so your agents do not execute unsafe instructions. Third, it gives you a consistent place to define policy across planners and workers rather than trying to encode policy in every prompt. Because Guardrails live in both the canvas and the SDK, safety becomes a reusable primitive, not an afterthought.
A word on model choice and reinforcement fine-tuning
AgentKit does not require you to use a single model for every step. The Evals suite supports third party models, which means you can benchmark candidates on your own datasets without changing tooling. When you find gaps that are consistent and important, consider reinforcement fine-tuning. It is generally available on o4-mini and in private beta for GPT-5. Two features matter in practice: custom tool call training that teaches a model when to reach for which tool, and custom graders that let you encode what performance means in your domain.
Treat fine-tuning as a follow-on to clean workflows and strong evals, not a first step. Otherwise you bake noise into the model and amplify the wrong patterns.
Strategy: how to position for the 2026 agent platform race
The next 18 months will be decisive. Here is a clear strategy that balances agility with compounding advantage.
- Bet on evaluation as your moat. Own your datasets and graders. If you switch vendors, your evals should travel with you. The team that measures best iterates fastest.
- Standardize connectors. Approve a small set of data sources in the registry and require product teams to use them. Fewer paths means fewer leaks and faster audits.
- Separate interaction from orchestration. Use ChatKit for the user interface and Agent Builder for workflows. Keep business logic out of the front end so UI changes do not break behavior.
- Embrace multi-agent patterns. Use planners, workers, and reviewers with explicit roles. Single giant prompts will not survive real-world complexity.
- Design for rollback. Version everything. Tie each production change to an eval run and keep a one-click rollback to the last good version.
- Run vendor bake-offs. Because Evals compares third party models, run quarterly tests against your datasets. Track cost, accuracy, and latency by task in a shared notebook.
- Build a human-in-the-loop habit. Add confirmation for first write actions, spot reviews for complex steps, and a clear path to escalate. Human oversight is your safety margin while agents learn.
Team shape and operating model
- Product owner. Defines the job-to-be-done, writes acceptance criteria as evals, and prioritizes tradeoffs.
- Evaluation owner. Curates datasets, writes graders, and runs trace grading. Treat this like quality engineering.
- Agent engineer. Owns Agent Builder workflows, tools, Guardrails, and integrations.
- Front end engineer. Embeds ChatKit and designs user affordances like confirmations and summaries.
- Data and security partner. Approves connectors, reviews scopes, and audits logs.
Schedule weekly triage on eval outcomes and monthly risk reviews. Agents drift when no one tends them.
Monday morning checklist
- Pick one workflow. Write a one-page brief with a target SLO and success definition.
- Enable only the two connectors you need in the registry. Keep it lean.
- Build a minimal planner and worker in Agent Builder. Add Guardrails with a default policy pack.
- Embed ChatKit in a staging page behind a feature flag. Ship it to five internal users.
- Log ten real runs. Turn those into your first eval dataset and run trace grading.
- Fix what the trace reveals. Only then consider prompt optimization or fine-tuning.
The bottom line
AgentKit does not make agents easy. It makes them tractable. By bundling a visual workflow builder, an embeddable chat interface, measurable evaluation, and governed connectors, OpenAI turned a pile of parts into a platform you can run a business on. Build with evaluation first, connectors under control, and versioned workflows. If you do, you can ship credible multi-agent systems this quarter and be ready for the platform cycle ahead.
For product leaders who want to put these components in organizational context, the Agent platform overview is a useful companion to this review, and our analysis of enterprise approaches in Agent Bricks marks the pivot to auto optimized enterprise agents rounds out the landscape.