AgentKit compresses the agent stack so you can ship fast
OpenAI unveiled AgentKit on October 6, 2025, unifying agent design, orchestration, evals, chat, and data connectors in one toolkit. See what shipped, what it replaces, and a practical plan to go from pilot to production in days.

Breaking: OpenAI collapses the agent stack into one kit
On October 6, 2025, OpenAI introduced AgentKit, a production toolkit that brings agent design, deployment, evaluation, and data connections under one roof. The company positioned it as a path from prototype to production without stitching together five different systems. If you have been juggling orchestration graphs, custom connectors, ad hoc evals, and a bespoke chat frontend, AgentKit is a significant change. OpenAI introduced AgentKit.
Think of the old agent stack as a home workshop. You had a bin of wires, separate power tools, and a hand drawn wiring diagram taped to the wall. AgentKit is closer to a factory station. The parts still snap together, but now there is one workbench with fixtures, measurement gauges, and a safety guard in place. This fits a broader industry shift toward packaged agent platforms. We have seen enterprise buyers lean into governed, centrally managed tools, a trend echoed in our look at OutSystems Agent Workbench GA.
What shipped and what it replaces
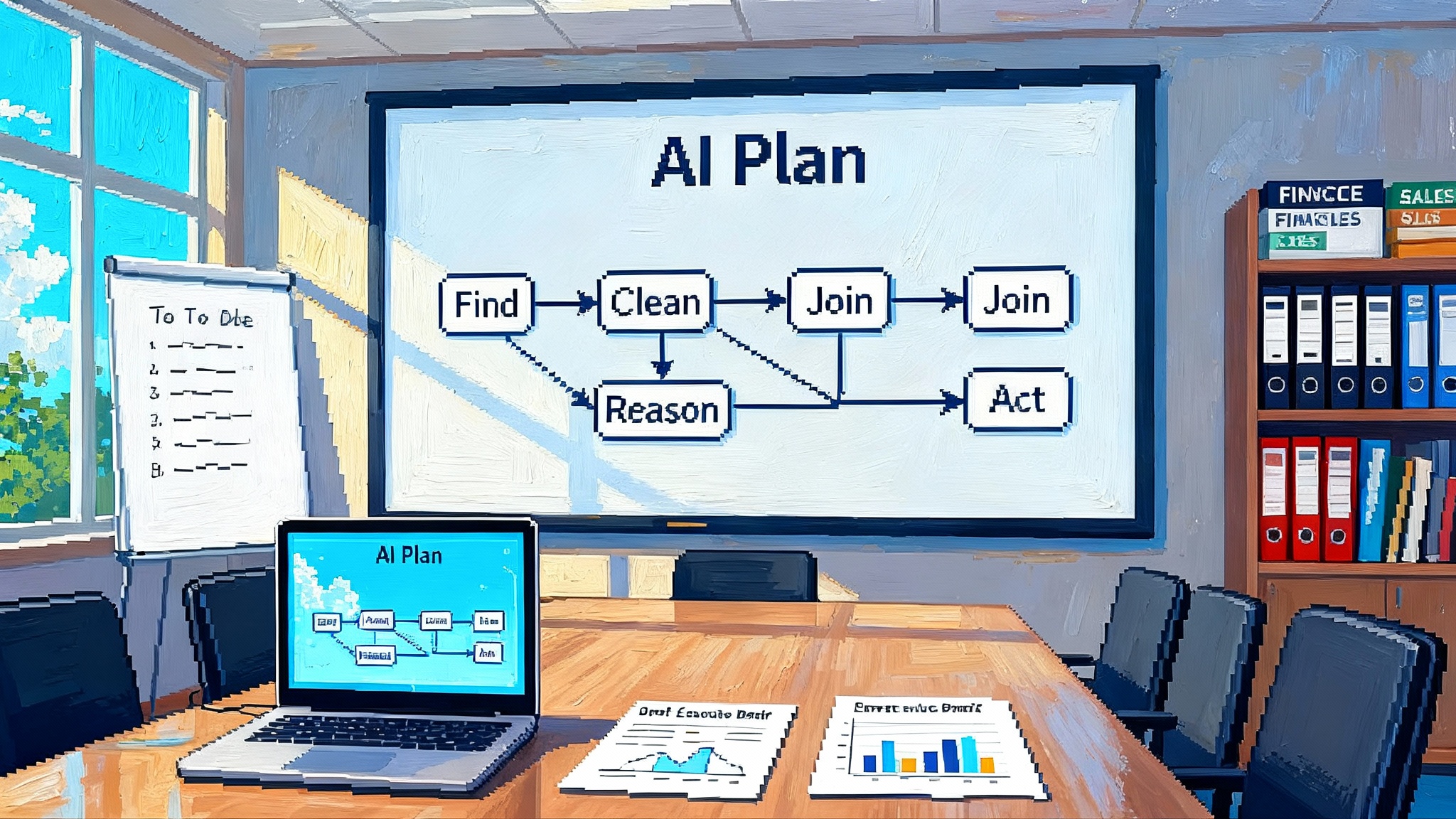
OpenAI bundled four core pieces. Each maps to a task that previously lived in a separate product or in your own glue code.
-
Agent Builder. A visual canvas to design and version multi agent workflows. You can drag nodes, connect tools, set guardrails, run preview traces, and store versions. In many teams this replaces a mix of directed graph libraries, whiteboard screenshots, and custom dashboards.
-
ChatKit. An embeddable chat surface with streaming, thread management, typing indicators, and theming. It lets you drop a production grade interface into your web app or product without rebuilding the basics of turn taking and context display.
-
Evals for Agents. Datasets, automated grading over traces, prompt optimization, and support for evaluating third party models. This takes the place of internal spreadsheets, one off grading scripts, and brittle test harnesses.
-
Connector Registry. A central admin control for data connections across OpenAI surfaces. It consolidates prebuilt connectors like Google Drive, SharePoint, Dropbox, and Microsoft Teams, plus Model Context Protocol integrations, and brings governance under a global admin console.
Availability matters for planning rollouts. ChatKit and the new eval features are generally available. Agent Builder is in beta. The Connector Registry is in early beta for organizations with the Global Admin Console. Pricing sits inside standard API model rates, so you do not need to budget a separate platform fee.
The compression is real
Before AgentKit, the do it yourself stack looked something like this:
- Orchestration with LangGraph or similar libraries to route between tools and agents
- Team based agent patterns with crewAI or homegrown equivalents
- A dev environment like Cursor to script prompts and tool calls
- Evaluation scripts, manual red teaming, and scattered datasets
- A front end chat interface you wrote yourself with streaming and states
- A sprawl of connectors wired through vendor SDKs and secrets
AgentKit compresses that into one mental model. Agent Builder handles orchestration and guardrails with versioning. ChatKit removes the need for a custom chat frontend. Evals centralizes tests and improvement loops. The Connector Registry gives administrators one place to approve and monitor data pathways.
There is also a foundation layer that makes the kit coherent. Since March, OpenAI has pushed the Responses API as the substrate that agents and tools run on. AgentKit leans on that substrate, which means you can compose model calls, tool use, and streaming with one primitive. If you remember juggling Assistants, Chat Completions, and homegrown tracing, the simplification is the point. See the Responses API overview.
What each module does, with concrete examples
-
Agent Builder. Picture a signal flow in audio software. Inputs, effects, and outputs are blocks on a timeline. Agent Builder is that for agents. Nodes can be a retrieval step, a tool call to your warehouse, or a policy check. Versioning turns a fragile diagram into a governed artifact that legal, security, and product can all review. Example: a fintech builds a buyer diligence agent. Compliance adds a sanctions check node and sets a hard fail policy. The team ships the new version under a change ticket instead of hoping a developer applied the right commit.
-
ChatKit. Chat is the user interface for most agents, but getting the basics right takes weeks. Streaming tokens smoothly, keeping a thread state, showing intermediate reasoning artifacts, and letting designers theme the experience is tedious work. ChatKit ships those primitives. Example: a customer support portal can drop in ChatKit, swap themes, and connect to the existing workflow id from Agent Builder. The first pilot can run without a frontend rewrite.
-
Evals for Agents. Your agent is only as good as the tests you run. Evals gives you datasets, trace level grading, and automatic prompt suggestions. If your research agent fails when a tool is rate limited, a trace grade highlights where it skipped a retry path. If your knowledge assistant drifts into speculation, automated graders mark hallucination risk on the exact step. Example: a media company loads 500 anonymized tickets, labels expected outcomes, and runs nightly evals. The team accepts or rejects suggested prompt edits and watches error bars shrink over a week.
-
Connector Registry. Data access is both the oxygen and the fire hazard for agents. The registry centralizes connection setup, secrets, and scopes. It also gives administrators one audit view across ChatGPT and the API. Example: an enterprise turns off personal Google Drive access and allows only a domain wide SharePoint connector with read only scope for pilot users. Security signs off without a custom secrets vault or a one off review.
The integrated stack vs the startup toolchain
Developers have built impressive systems with LangGraph, crewAI, Cursor, and a handful of open source sidekicks. That ecosystem will not disappear. It still offers flexibility, local or hybrid execution, and deep customization.
Where AgentKit wins:
- Time to first pilot. You can design, embed, and evaluate without choosing six different libraries and wiring tracing between them.
- One substrate. Running on the same Responses API reduces state mismatches between prototypes and production.
- Safety in the loop. Guardrails and policy checks can live inside the graph, not in a separate proxy.
- Admin grade connectors. A central registry for data is a big ask from security and compliance teams.
Where the startup toolchain still shines:
- Exotic topologies. If you want unconventional control loops or specialized schedulers, LangGraph is still a blank canvas.
- Model pluralism. crewAI or homegrown runners make it easier to mix providers, tune routing, or run local models.
- Deep editor workflows. Cursor and similar tools provide agentive coding loops that are not about end user chat at all.
- Self hosted execution. If you need hard isolation, on premise deployment, or air gapped environments, the open stack is still the path.
The practical takeaway is to pick your battles. Use AgentKit when consistency, speed, and governance are the priority. Use the startup toolchain where flexibility, model autonomy, or deployment control are the priority.
Where startups can still win
OpenAI just compressed the stack, but there is surface area left for differentiation.
-
Domain specific skills. Build agents that know the tribal rules of a vertical and own its tools. A life sciences agent that understands assay workflows, lab calendars, and instrument quirks will beat a generic agent every time. Encode domain schemas and test them with evals that mirror real lab logs.
-
Enterprise governance and safety. Many organizations need policy engines, approval gates, red team suites, and audit trails that reflect their risk model. There is room for focused products that plug into AgentKit graphs, provide independent logging, and deliver executive ready reports. If you buy the thesis that metrics are replacing dashboards in daily operations, revisit our analysis on the end of dashboard culture.
-
On premise and private cloud. Some customers cannot move data to a shared cloud. Replicate the ergonomics of AgentKit with self hosted orchestration, match the node semantics, and offer a compatibility layer. Your pitch is simple. Same developer experience, same templates, strict isolation.
-
Multi model cost control. There is a market for routers that decide when to use a large reasoning model, when to stick to a smaller route, or when to answer from a cache. Evals that compare third party models make this concrete. Startups can offer policies like budget caps per workflow, fairness across teams, and spot token markets.
Architecture patterns to steal
-
Customer support resolver. Build a graph that classifies intent, retrieves account context, calls a billing or shipping tool, and drafts a resolution. Use ChatKit for the surface and an agent handoff node to escalate with full trace context. Add Evals that measure first contact resolution, time to answer, and policy compliance.
-
Research and synthesis. Build a multi step loop that searches, clusters sources, drafts, and self critiques. In Evals, grade citations, coverage, and novelty. Use a connector to your approved knowledge base and disallow the rest during sensitive tasks.
-
Sales prospecting. Combine a lead enrichment tool, a tone guardrail, and a calendar scheduler. Evals measure reply rate and compliance with regional outreach rules. ChatKit powers a concierge mode inside your product so account executives can intervene.
-
Retail assistant to revenue. Pair product retrieval, coupon logic, and order status tools with a chat surface. Then run A and B flows that test tone and incentive size. For a deeper picture of value capture in consumer agents, see our breakdown of the AI shopping agent playbook.
A pragmatic build guide to ship in days
Day 0: Define success and guardrails. Pick one task and one metric for success. For example, cut time to resolve support tickets by 30 percent without raising handoffs. Write a simple policy that the agent must follow, including never changing customer entitlements and never asking for full payment information.
Day 1 morning: Sketch the workflow in Agent Builder. Start from a template if one fits. Name every node with a verb and a measurable outcome. Add a policy check node where failure paths are explicit. Connect just one data source through the Connector Registry for the first test. Run a dry trace that shows every step.
Day 1 afternoon: Embed ChatKit. Create a minimal backend endpoint for session tokens. Drop the chat component into a staging page and theme it to match your brand. Put the workflow id behind it. Sit a product manager and a support lead in front of it for an hour and watch them use it. Capture every failure.
Day 2 morning: Instrument Evals. Build a dataset of 50 to 100 real but anonymized tasks. Add trace grading for the core failure modes you saw in the pilot. Turn on automated prompt suggestions, but do not auto apply them. Route five failure cases to a smaller model to explore cost control.
Day 2 afternoon: Expand connectors carefully. Add only the minimum data sources needed. Set scopes to read only until you are confident in your policy checks. Invite a security reviewer to inspect the connector list and the graph nodes. Assign an owner for each connection and document rotation procedures.
Day 3 morning: Run a supervised pilot. Put 10 percent of real traffic through the agent with a human in the loop. Track your headline metric, cost per resolution, and the distribution of failure causes by node. Reject any prompt changes that help the top metric but hurt compliance or tone.
Day 3 afternoon: Prepare for production. Lock a version in Agent Builder. Write a rollback plan that points to the last good version. Set alerts on evaluation drift, tool call failures, and token costs. Document a handoff process to humans with full trace context.
An evaluation checklist you can adopt today
Adopt this list, then tailor it to your risk posture.
- Task success. Is the goal achieved as defined by your product spec
- Tool call accuracy. Did the agent call the right tool with the right parameters on the right step
- Hallucination rate. Did the agent fabricate facts or overstate confidence
- Safety and policy adherence. Did the agent follow required policies at each decision gate
- Privacy posture. Are personal identifiers masked or removed where required
- Robustness under stress. What happens with large inputs, rate limits, network faults, or partial outages
- Cost efficiency. Tokens per resolution, tool call spend, and variance by traffic pattern
- Latency and throughput. End to end time and the slowest step in the trace
- Human in the loop handoff. Is the escalation path clear and does the human receive full context
- Drift over time. Do weekly evals show changes in behavior as data sources or models evolve
For each item define an acceptable threshold, an alert, and a remediation playbook. Tie those to specific nodes in your Agent Builder graph so you can roll forward and back with confidence.
Costs, availability, and the fine print
Plan around two facts. Agent Builder is in beta and the Connector Registry is rolling out to organizations with the Global Admin Console. ChatKit and the new eval capabilities are generally available. All are bundled into standard API model pricing. Confirm the current status in your admin console before you commit a launch date.
Expect to spend most of your time on data scoping, security reviews, and evaluation design. The build time falls sharply when the interface and orchestration are prebuilt, but governance does not. Budget days for connector approvals and for legal reviews of policies inside your graph.
Vendor risk and how to mitigate it
-
Lock in through interfaces. Keep a thin adapter between your business logic and Agent Builder nodes. If you must migrate, you can port node semantics to another runner.
-
Keep your tests portable. Store eval datasets and trace grading logic in a format that other runners can understand. If you ever need to compare models or providers, your tests move with you.
-
Isolate credentials. Use the Connector Registry for scope and approval, but store secrets under your corporate standard. Rotate on your cadence, not just the platform’s.
-
Measure cost routes. Use Evals to trial smaller models or different providers where allowed, and document when the router should switch. Cost control is a design choice, not a last minute patch.
The bottom line
AgentKit marks a shift from a hobbyist era of agents to an operational era. The kit does not remove the need for thoughtful design, policy, and evaluation. It removes a lot of scaffolding. If your goal is value in market within days, build a narrow workflow in Agent Builder, put ChatKit in front of it, wire only the connectors you need, and run Evals every night. The startups that win will not be the ones that rebuild the same scaffolding. They will be the ones that encode real domain skill, ship with enterprise governance, and treat evaluation as a product feature rather than a chore.