AgentKit is live: the standard stack for enterprise agents
OpenAI’s AgentKit sets a new baseline for building and running enterprise agents with a visual builder, embeddable chat, rigorous evals, and a governed connector registry. Here is why this launch matters and how to ship in 60 days.

A new baseline for agent development
On October 6, 2025, OpenAI introduced AgentKit, a unified toolkit that takes agents from whiteboard to production in one place. The release pairs a visual Agent Builder, an embeddable ChatKit for user interfaces, expanded Evals for measurement and improvement, and a Connector Registry for governed access to data and tools. The goal is a predictable development lifecycle, stronger governance, and fewer integration potholes. For the official overview, see Introducing AgentKit.
This is not a small iterative release. It codifies a standard agent stack that product, security, and platform teams can all agree on. Until now, many companies combined orchestration code, custom connectors, isolated prompt sandboxes, ad hoc evaluation scripts, and weeks of front end work just to run a pilot. AgentKit replaces that patchwork with one backbone that is versioned, observable, and policy aware.
What is inside AgentKit, in plain terms
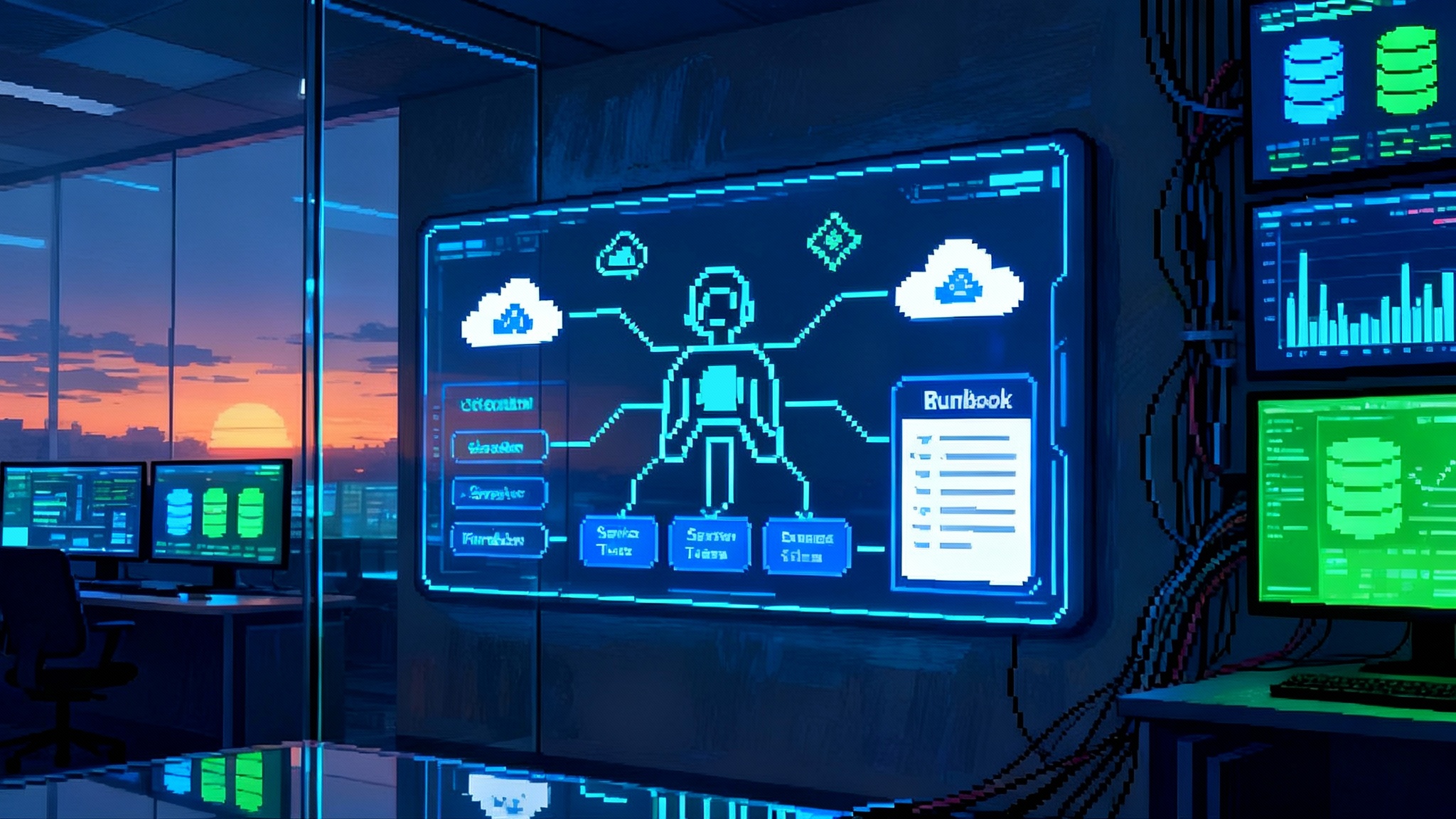
Think of AgentKit like a modern factory. The Agent Builder is the assembly line, ChatKit is the storefront where customers interact, Evals is the quality control lab, and the Connector Registry is the loading dock that manages which trucks can bring parts in and take results out. Each piece can be used alone, but the real value shows up when they run together.
Agent Builder: the assembly line
Agent Builder gives you a visual canvas to compose multistep workflows with nodes for tools, guards, branching logic, and prompts. You can drag and drop steps, test in preview, and ship versions with proper change control. That means a product manager, a security reviewer, and an engineer can inspect the same flow and agree on what happens when. It also means that if a data source or rule changes, you bump the version, rerun your evals, and roll forward with confidence. Agent Builder includes support for prebuilt templates and a Guardrails layer to help reduce risky behavior such as exposing personal information or following jailbreak instructions.
A concrete example: a finance approvals agent might read purchase requests from a queue, summarize vendor terms, check a policy repository, route edge cases to a human, and post results back to a system of record. In Agent Builder, those are individual nodes with explicit inputs and outputs. When legal tightens a threshold, you update one node, create a new version, and push it behind a feature flag while Evals verifies that accuracy stayed within bounds.
ChatKit: the storefront for users
ChatKit is a toolkit for embedding chat based agent experiences in your product without rebuilding the user interface. It handles conversation state, identity, theming, streaming tokens, and input attachments, which commonly add one or two weeks to every agent project. It slots over the Responses API and built in tools like web search, file search, code execution, and computer use so teams can focus on behavior rather than scaffolding. For platform context and examples across the agent lifecycle, review Build every step of agents on one platform.
What you put inside that chat window matters just as much. With the core APIs, your agent can cite sources, retrieve internal knowledge, run analysis, and carry out multistep tasks that would normally require separate microservices. ChatKit wraps this foundation so you can spend your time on task design and policy rather than reinventing UI primitives.
Evals: the quality control lab
Evals began as a framework for testing prompts and behaviors. AgentKit expands it with datasets you can grow over time, trace grading to evaluate end to end workflows, automated prompt optimization that suggests improvements, and support for evaluating third party models. In practice, Evals lets you turn a fuzzy goal like make the assistant more helpful into a measurable target like raise intent classification F1 from 0.78 to 0.90 while keeping hallucination rate under 1 percent. You can then gate releases on these checks before you promote a new version of the agent.
There is a cultural impact here. Evals makes subjective debates about prompt phrasing give way to objective evidence. A taxonomy of failure modes, a curated dataset, and stable graders shift the discussion from I feel this is better to the approval agent meets the accuracy and safety bar for this population. That is what lets enterprises ship fast without losing control.
Connector Registry: the loading dock
Enterprises need to decide which data the agent can see and which tools it can call. The Connector Registry provides a central place to register approved integrations across ChatGPT and the API. That includes cloud storage like Google Drive and Dropbox, developer systems like GitHub, collaboration platforms like SharePoint and Microsoft Teams, and custom connectors built with the Model Context Protocol. Admins configure access once, then teams reuse those connections in multiple agents. The registry is beginning its beta rollout and requires a Global Admin Console, which aligns with how large organizations coordinate domains, single sign on, and multiple API organizations.
A registry is more than convenience. It reduces the number of shadow integrations, makes audits faster, and helps privacy teams reason about data boundaries. When a vendor relationship changes, a single admin action can remove the connector across your estate and all dependent agents will fail closed until a replacement is configured.
Reinforcement fine tuning and model shaping
OpenAI is also expanding reinforcement fine tuning for reasoning models. It is generally available for o4 mini, with a private beta for GPT 5. Features like custom tool calls and custom graders let you teach models when and how to use your tools and what good looks like for your domain. You can use this to push the last ten percent of performance on complex workflows where generic prompting tops out.
Why this looks like an enterprise inflection point
-
Standardization lowers coordination costs. AgentKit defines a common language for product, security, and platform teams. Visual workflows and versioning align with change management practices. The Connector Registry brings identity, access, and data governance into the same frame as development.
-
Reliability and speed improve together. When evaluation is first class, teams can ship rapidly while enforcing quality gates. Platform primitives like ChatKit and the Responses API reduce iteration cycles and front end lift, which are exactly the bottlenecks that stall pilots.
-
Procurement and risk become tractable. With admin controls and clear connector scope, legal and security reviews go faster. A single vendor contract and audit surface replaces a web of small tools and throwaway services.
-
A path to continuous improvement. Evals, data collection, and reinforcement fine tuning create a loop where real world performance can be measured, then improved with data and training, not just prompt wordsmithing. That loop turns an agent from a demo into an asset.
How AgentKit reshapes the agent tooling landscape
The agent ecosystem has grown fast, from orchestrators to evaluation frameworks to front end kits. AgentKit does not erase that work. It reorganizes it.
-
Databricks and data platforms. If your data engineering stack lives on Databricks or an equivalent lakehouse, you will continue to ingest, transform, and govern data where it belongs. AgentKit slots on top as the orchestration and experience layer. Treat your lakehouse as the gold source, expose curated tools and data via connectors, and let Agent Builder handle the last mile. The boundary is clean. Data platforms own data prep and governance at rest. AgentKit owns interactive reasoning and controlled tool use in flight.
-
LangGraph and open source orchestration. Complex graphs with custom policies and on premises deployments remain good fits for LangGraph and similar stacks. The pivot is to wrap those graphs as tools that AgentKit can call, or to host them behind a service endpoint the agent invokes. You get the best of both worlds: custom graph logic, standardized evaluation, governance, and a consistent user interface via ChatKit.
-
Evals as the universal metric layer. Even if part of your stack is vendor neutral, you can run your evals in AgentKit against third party models. That reduces tool sprawl by making quality measurement a shared artifact that outlives any one component.
-
Connectors as the policy boundary. Instead of sprinkling credentials across microservices, you register and approve connections once. When a new agent is proposed, the security question becomes whether it uses an approved connector with the right scope, instead of a long discovery process.
This reorg matches broader platform moves we have tracked. When Amazon formalized agents as the unit of work, we noted how standardized primitives accelerate teams. See how that idea shows up in the Quick Suite general availability analysis. When Google pushed computer use into the browser, it showed where agent interfaces are headed. That trend is explored in our Gemini 2.5 browser control piece. And when chat became the enterprise command line inside collaboration tools, adoption surged. For that shift, revisit why Slack’s bot matured into a command surface.
Reliability and cost control, translated into mechanisms
If you are accountable for uptime, accuracy, and budget, you need more than slogans. AgentKit helps at several layers:
-
Evaluation gates. Define task specific metrics and thresholds, build a dataset that mirrors your production inputs, and use trace grading to catch failure modes like tool misuse or missing retrieval. No release should go out without passing these gates.
-
Guardrails. Enable prebuilt policies to detect risky content and prevent data leakage. Combine this with role based access and connector scopes so that an agent cannot fetch what it should not see.
-
Cost budgets and model strategy. Use a tiered approach. Route easy cases to a fast, lower cost model. Escalate hard cases to a stronger model. Set timeouts and step limits to prevent runaway tool calls. Distill specialized tasks into lighter models once patterns stabilize, then lock budgets per tenant or per agent.
-
Observability and rollback. Version agents, collect traces, and maintain a known good baseline. If a regression slips through, roll back the version or toggle the feature flag. With ChatKit handling the interface, you avoid redeploying front end components when you change agent logic.
-
Security in depth. Keep secrets in the connector boundary, not in business logic. Require scoped service accounts where available. Treat agent prompts and tool configuration as code that must pass review and change control.
A 30 60 90 day plan to ship by Q4 2025
You are starting in mid October 2025. Sixty days lands in mid December, inside Q4. The plan below gets you to a general availability release by day 60, with day 90 focused on scale up and cost reductions.
Days 0 to 30: align, prototype, and instrument
Outcomes by day 30
- Define one high value, bounded workflow. Examples: refund approvals up to a threshold, contract clause extraction for specific templates, or sales research briefs in defined industries. Write an explicit success specification that includes accuracy, safety, latency, and a monthly cost cap.
- Stand up the baseline agent in Agent Builder. Use a minimal tool set. For example, add web search for citations where needed, file search over a curated folder, and exactly one system of record. Keep the first version rule based on when to call which tool. Document assumptions in the canvas.
- Embed a working interface in a staging app with ChatKit. Ship something your internal users can click. Use the kit’s primitives rather than a custom chat. Recruit ten pilot users and schedule two feedback sessions per week.
- Establish governance. Register only the connectors you need for the pilot and assign least privilege scopes. Set up a service account if supported. Confirm data handling with legal. Configure role based access in the Global Admin Console if available.
- Build the evaluation backbone. Curate 150 to 300 representative tasks with ground truth or gold standards. Add trace grading to catch tool misuse and hallucinations. Decide release gates, for example intent accuracy above 90 percent, citation coverage above 95 percent, and no safety violations.
- Model and cost baselines. Record token usage, tool call frequency, and latency by task type. Set alert thresholds. Start a distillation plan if your task is stable and high volume.
Checklist
- Success specification approved by product, security, and finance
- Agent Builder project created with version 0.1 tagged
- ChatKit interface integrated in staging, with user sign in and basic theming
- Connectors registered and scoped; audit log verified
- Evals dataset created with grading scripts; release gate thresholds in place
- Budget dashboard shows cost per task and per user
Days 31 to 60: harden, measure, and release
Outcomes by day 60
- Expand evals and fix failure modes. Double your dataset size and add automated prompt optimization. Create a clear error taxonomy with owner assignments. Track improvements with weekly trend lines.
- Add guardrails and safety tests. Enable prebuilt policies for sensitive data and jailbreak detection. Confirm that red team prompts fail safely. Log masked events for audit.
- Lock down governance. Use the Connector Registry as the single source of truth. Run an access review and revoke anything unused. Document a break glass procedure and simulate it once.
- Finalize the user experience. Address feedback from pilots, polish messages, add citations where appropriate, and make sure empty states are helpful. Keep customization light so future ChatKit updates are easy to adopt.
- Release to general availability. Gate traffic with a feature flag, start with a 20 percent rollout, and monitor. Define rollback criteria in advance. Publish your service levels: accuracy, latency, and monthly budget boundaries.
- Optional performance push. If your task benefits, start reinforcement fine tuning on o4 mini with custom graders to cement tool use discipline.
Checklist
- Evals dataset doubled, with prompt optimizer incorporated
- Guardrails enabled, safety regression tests green
- Connector audit complete, policies documented
- ChatKit release candidate approved by design and support
- Launch playbook executed, including rollback drill
Days 61 to 90: scale, reduce cost, and expand scope
Outcomes by day 90
- Distill and right size. Train a distilled model for common patterns to cut cost and latency. Keep an escalator to a stronger model for rare hard cases. Lock per tenant budgets and step limits.
- Broaden data safely. Add one or two more connectors through the registry, such as a ticketing system or a second content repository. Expand evals to include these data sources and update safety checks.
- Strengthen operations. Add synthetic canary tasks, saturate load tests, and on call runbooks. Set up dashboards for tool errors, timeouts, and cost anomalies.
- Plan the next agent. Use lessons from the first launch to choose a second, adjacent workflow. Reuse the evaluation backbone and connectors. Only the business logic should change.
What to watch next
OpenAI signals that a standalone Workflows API and agent deployment options to ChatGPT are on the roadmap. Expect deeper hooks between Evals, Guardrails, and deployment so that test results can promote or block versions automatically. Also expect the Connector Registry to grow and to integrate more tightly with global admin controls across ChatGPT Enterprise and Education. These pieces should make it easier for security teams to bless more use cases with less custom review.
The bottom line
AgentKit turns agent development from an art project into an engineering discipline. A visual builder makes behavior legible and versioned. ChatKit removes weeks of interface work and standardizes how users interact. Evals moves quality discussions from intuition to evidence. The Connector Registry creates a single front door for data and tools that security can govern. With these in place, the agent layer becomes a new kind of middleware in the enterprise stack. If you start today, a disciplined 60 day push can get a reliable, governed agent into production before the quarter ends, and the next 30 days can drive cost and performance down further. That is what an inflection point looks like when it is real.