Dialing Up Thinking Time: The New AI Pricing Frontier
In 2025, intelligence became a slider. Users will soon choose how long models think before they respond, reshaping product design, pricing, safety, and governance. Here is how to ship a visible reasoning meter people trust.
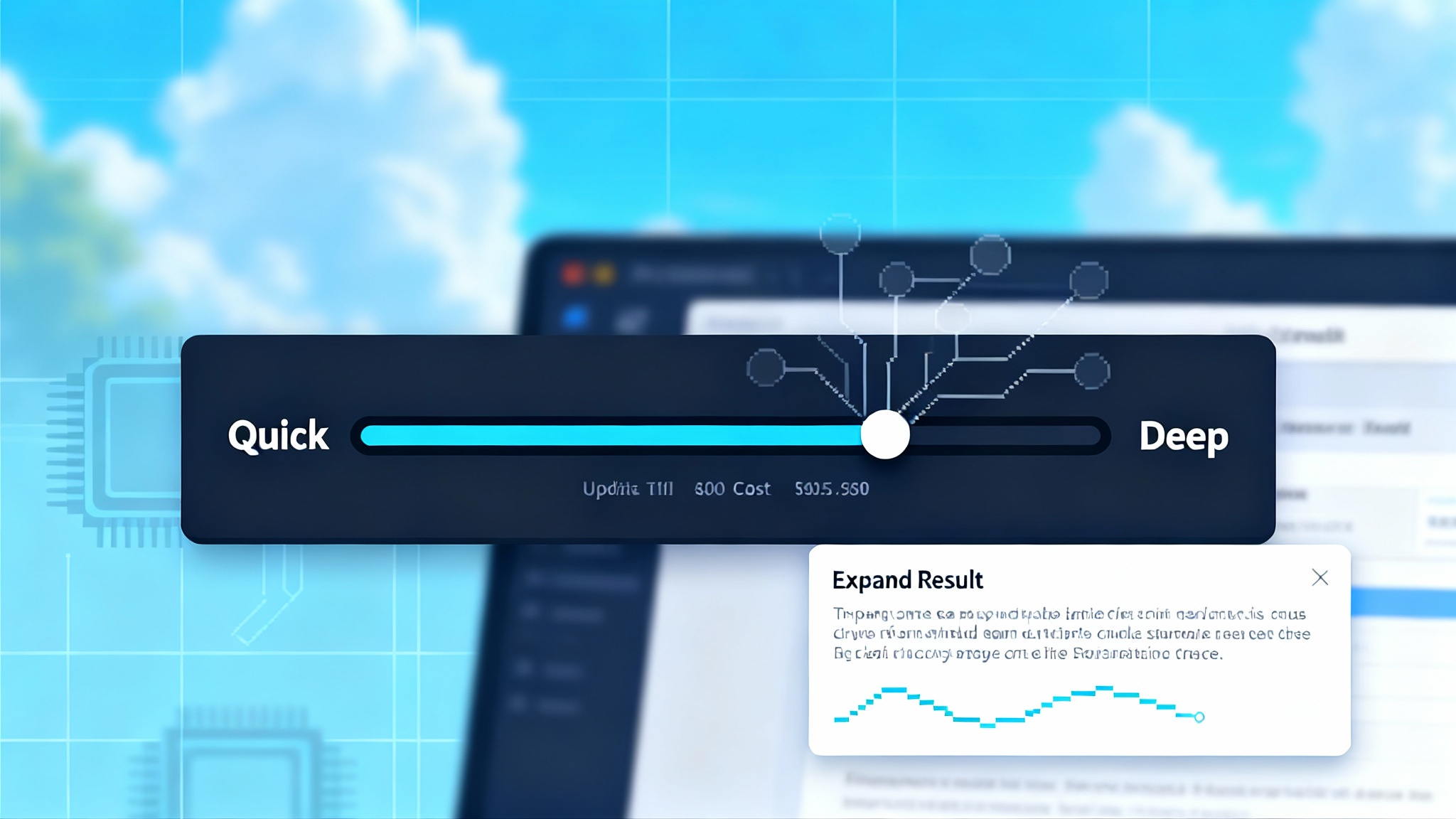
The week AI made time a first class feature
It finally happened. In 2025 the industry stopped treating intelligence as a fixed trait packaged inside a model and started treating it like a dial you can turn. NVIDIA put a spotlight on test time scaling with Blackwell Ultra, describing infrastructure designed so models can spend more compute during inference to explore alternative solution paths and produce better answers. That framing is not a side note. It is the headline, and it signals a new design language for AI products. See the official description in the NVIDIA Blackwell Ultra platform.
At the same time a new wave of reinforcement learning style reasoning models moved from labs into products. OpenAI’s o1 family turned reasoning time into a visible control for developers, exposing a parameter that lets you trade speed and cost for deeper thought. The company documents this option in the OpenAI o1 developer announcement.
Put those two moves together and you get a clean thesis: intelligence is shifting from fixed model capacity to variable, user dialable thinking time. That reframes how we design interfaces, how we price usage, how we manage risk, and how we govern who decides how much compute a model can spend on your behalf.
Why this matters now
For years most apps treated inference as a one shot guess. You sent a prompt, the system responded, and maybe you nudged it with a follow up. Today’s reasoning systems do something different. They search. They simulate. They sketch an internal plan, test variations, then decide. That extra thought costs time and money, but it also cuts down on brittle failures and silly mistakes.
If that sounds abstract, think about a camera. You can keep the same sensor but improve the photo by changing exposure time. A longer exposure gathers more light and reduces noise as long as the subject is not moving too fast. Reasoning time is exposure for thought. Same model, different results, because the system let itself gather more signal before committing to an answer.
This dovetails with our broader view that time is not a nice to have but a first order variable in capability. For background on how longer horizons change outcomes, see our argument on why long horizon agents win.
The product shift: give users a reasoning meter
If intelligence depends on thinking time, the interface must show thinking time. A clear, legible control belongs in the product, not hidden behind a settings page.
A practical design looks like this:
- A visible meter that ranges from Quick to Deep. Quick gives an answer in seconds. Deep buys minutes of structured reasoning, tool use, and self checks.
- A plain estimate of cost and latency before the user commits. Show something like “about 7 seconds and 3 cents” for Quick, “about 40 seconds and 22 cents” for Deep, with a small info icon explaining why deeper costs more.
- A preview of what deeper does. When the user hovers over Deep, reveal examples: run multiple solution paths and compare, call external calculators, verify cited numbers.
- A per task override. Default to Quick for simple questions. Nudge to Standard when the system predicts a complex prompt. Offer Deep when it detects high stakes such as legal phrasing, medical context, critical code changes, or financial calculations. Give the user the final say.
- A post answer trace. After a deep run, let users expand a trace showing the plan steps and checks that were performed. Do not flood them with raw chain of thought text. Summarize what was done and why that improved confidence.
This meters and traces pattern should become as normal as playback speed in a media player. It earns trust because it makes invisible work visible and it explains tradeoffs in plain language.
A quick example
Imagine a product designer drafting a customer email. In Quick mode the agent proposes a concise draft in five seconds. In Standard it generates two alternative tones, compares them to brand guidelines, and flags a claim for verification, taking 18 seconds. In Deep it also checks recent support tickets for phrasing that resonates and runs a toxicity filter on the final copy, taking 45 seconds. The user sees the time and the cost up front and the trace after, then chooses which version to send.
Pricing: from tokens to deliberations
Pay per token got us this far. Pay per deliberation is what comes next. Reasoning heavy runs are not just longer outputs. They are multi stage internal searches and tool calls with different compute bills and risk profiles.
Here are pricing models that match how users think:
- Depth tiers by default. Offer Quick, Standard, and Deep as named run modes with transparent prices. Map those to internal parameters like number of reasoning steps, number of sampled plans, allowed tool calls, and maximum wall clock time. If the run escalates, tell the user why and how that changed the price.
- A budget slider for power users. Let them set a per query dollar cap and a monthly cap. If a run hits the cap mid deliberation, the agent should stop, summarize what it tried, and offer the option to continue.
- Packaged depth for enterprises. Bundle Deep runs into seats or case allowances. A research seat could include 1,000 Deep runs per month with priority scheduling and higher tool use limits, while support seats default to Standard with burstable upgrades.
- Event based discounts. If the agent verifies a claim with independent evidence or unit tests, credit a small portion of the cost back as a reliability rebate. That makes quality an economic win, not just a moral one.
Under the hood vendors should unify pricing units across steps. A simple approach is to treat everything as planned compute seconds, whether tokens, tool calls, or retrieval. At the product layer keep it in human terms: seconds and cents.
What to put on the receipt
A great billing artifact has three sections:
-
Thinking time. Seconds and estimated cost spent on internal reasoning, parallel branches, and self checks.
-
Tools and retrieval. Calls to calculators, search APIs, code runners, or vector stores, with time and cost per call.
-
Output. Tokens generated and their cost.
Users should be able to compare two runs side by side and instantly see what deeper thinking bought them.
Safety: longer thought can reduce failure modes
Longer is not always better, but deliberate thought helps reduce predictable failures. Three concrete mechanisms matter:
- Self consistency. When the model runs multiple solution paths and picks the most consistent answer, it reduces the odds that a single mistaken chain dominates. This is especially powerful in math, coding, and formal logic.
- External checks. Reasoning runs should include calls to calculators, unit tests, parsers, and data validators. A code fix that passes unit tests is safer than a clever textual patch.
- Refusal quality. With more time, the agent can analyze context and provide safer refusals with help, not just hard no answers. It can suggest adjacent legal tasks or point to trusted resources.
There are safety tradeoffs. Longer runs expose larger attack surfaces where jailbreaks try to hijack a later step, or where tool outputs can be manipulated. The mitigation is orchestration:
- Add budget aware guardrails. High risk domains should require a safety check before the agent escalates to Deep.
- Gate sensitive tools. If a prompt may trigger financial actions, require explicit confirmation and show the planned transactions before execution.
- Log verification steps. Keep a signed record of which checks were run and what passed. That helps audits and allows teams to improve the weakest checks over time.
Treat safety tools as part of the deliberate run, not as a separate compliance layer. This connects directly to the case for auditable model disclosures. If the agent needs more time to verify and de risk a response, that time should appear on the bill and in the trace.
Governance: who decides how much compute is spent for you
Giving models a credit card for compute without guardrails is not governance. As reasoning time becomes a dial, we need policies that specify who can turn the dial, how far, and under which conditions.
- User primacy by default. The end user should see and control the depth of a run. Hidden escalations erode trust.
- Admin policies for organizations. Teams need caps per project, role, and environment. A staging environment might allow Deep for experiments, while production routes default to Standard and require approval to escalate.
- Task based rules. Safety teams can encode rules like “Deep is required for contract generation” or “Deep is prohibited for social content replies.” The agent should explain when a policy forces a depth change.
- Transparent scheduling. Queues should reflect both fairness and priority. If a Deep run will wait, show the estimate and offer alternatives, such as splitting the task into two faster Standard runs with an extra verification step.
This is where platform design meets sovereignty. The governance dial will live inside the assistant layer and the operating model that surrounds it. For a broader view of how assistants become control points, see our essay on apps, agents, and governance.
What this means for builders right now
You do not need to redesign everything to ship a reasoning meter. Start with these steps:
-
Add a depth control. Expose Quick, Standard, and Deep and wire them to concrete internal limits: number of plans, maximum tokens for internal thinking, number of tool calls, and maximum wall clock time. Avoid mystery modes. Label what the agent will do differently at each depth.
-
Show the bill before and after. Pre run, estimate time and cost. Post run, show the actual bill split by thinking, tools, and output. Keep the format constant so users can compare runs. Highlight when verification steps reduced risk or caught an error.
-
Predictively nudge. Train a simple classifier to detect prompts that are likely to benefit from deeper thought. Offer a one click nudge to Deep with a sentence that explains why. Make the nudge reversible with a single click.
-
Bake in checks. Tie deeper runs to more verification. If the user buys time, spend it on self consistency, tests, and citations that add confidence, not just on longer text. Show which checks ran and which ones passed.
-
Instrument success. Track error rates, user corrections, refund rates, and time to useful output by depth. Expect a U shaped curve: Quick is great for easy tasks, Deep wins on hard ones, and Standard covers the middle. Use this to tune defaults per user and per workflow.
-
Fail gracefully. When a run hits a budget or time cap, return the partial plan, the best candidate answer, and what the agent would do with more time. Let the user choose whether to continue. If they do, pick up exactly where you left off.
-
Make policies legible. Show the policy that allowed or blocked escalation. If a compliance rule requires Deep for certain documents, annotate the run with that rule and link to the policy page.
-
Close the loop with teams. Provide weekly summaries by project: how many Deep runs were used, what quality gains were observed, where verification caught issues, and how much was saved by avoiding unnecessary depth.
A plain English primer: what is test time scaling and why it works
Test time scaling means spending more compute during inference to improve answer quality. Imagine you ask an agent to debug a complex function. In Quick mode it scans the code and suggests a single fix. In Deep mode it explores multiple hypotheses, runs your unit tests, and compares results. That extra computation lets the agent search the space of possible fixes and pick a better one.
Under the hood this can involve:
- Sampling alternative solution paths and picking the majority result.
- Running small targeted tools like calculators or parsers to check intermediate steps.
- Using search strategies that branch and backtrack, similar to how chess engines explore move trees.
- Parallelizing branches, then reconciling the outcomes with a vote or a verifier.
The hardware matters because branching is expensive. The software matters because developers now have parameters that let them choose the budget per task. Together they turn intelligence from a fixed block into an adjustable budget.
A new mental model for teams
- Intelligence is not a static score. It is the product of capacity, data quality, and time.
- Reasoning time must be a visible choice. Users should see it, understand it, and control it.
- Pricing should match the choice. If users select deeper thought, they should pay more, with a clear preview and receipt.
- Safety is part of the run. Use extra time to verify, test, and cite, not just to ramble.
- Governance should be programmable. Policies should encode when to default to deep, when to cap, and when to explain an escalation.
The competitive angle in 2025
Vendors that normalize pay per deliberation will outpace those that hide everything behind token totals. Why? Because customers buy outcomes. If a contract generator costs 25 cents in Quick and 60 cents in Deep, a legal team can make an informed choice per document and per deadline. If an on call engineer can pay for a deeper fix only when needed, they will gladly do so during an outage and save it during calm.
We are also seeing an ecosystem move toward inference side acceleration. Cloud providers are packaging rack scale systems that act like single accelerators for large batches of reasoning queries. Workstation vendors are starting to sell deskside rigs that can power deep local inference for sensitive data. On the software side, platforms are adding explicit controls for reasoning effort, and marketplaces are beginning to advertise models not just by quality but by how they scale with more time.
This is not just performance theater. It changes how organizations plan budgets, design workflows, and explain AI decisions to stakeholders. When the bill and the trace say why the system spent 42 seconds and 23 cents to check a claim, a manager can approve that behavior and set a policy to repeat it when the stakes are similar.
The case for a slightly accelerationist stance
We should embrace inference side compute as a path to more capable and safer agents, with one condition. Make the cost, time, and control of reasoning legible. When users can see and adjust the budget, when teams can encode policies, and when bills reflect real checks and not just longer output, we get the best of both worlds: faster progress and fewer surprises.
Call it a social contract for machine thought. Users pick how hard the system should think. Builders show what that costs and what it buys. Hardware vendors push the ceiling so test time scaling has room to breathe. Regulators ask clear questions about defaults and consent rather than blocking the dial outright. For a policy frame that complements this, consider the idea that assistants are becoming gateways with enforceable rules, which we explored in apps, agents, and governance.
The bottom line
In 2025 intelligence is becoming a slider. The winners will be the companies that turn that slider into a trustworthy product experience: a visible reasoning meter, fair pricing for deliberation, safety checks that use extra time to verify rather than waffle, and governance that encodes who gets to turn the dial. The technology is here. The design patterns are straightforward. The upside is real. Build it so that when we dial up thinking time, users know exactly what they are getting and why it is worth it.