Sellm and the Birth of GEO: Win Placement in AI Answers
Sellm’s September 2025 launch of a ChatGPT rank tracker signaled a new growth channel. Learn how to measure answer share, earn tool inclusion, and stand up a GEO stack that compounds across assistants.
Breaking: the first GEO signal just flashed
In September 2025, Sellm introduced a platform that tracks how brands surface inside ChatGPT answers. It treats the assistant’s output like a results page and your appearance like a rank. That single release landed with the force of a category name: Generative Engine Optimization. Not a buzzword. A scoreboard.
For years, search engine optimization trained teams to chase ten blue links. Now assistants are the default front door for everything from research to shopping to support. Users ask, assistants answer, and the path to purchase compresses into a single screen that blends text, citations, and tool calls. The question for growth leaders is not whether assistants will become a primary channel. It is whether your brand will be present when the answer is formed.
Sellm’s launch is the clearest early proof that placement inside large language model outputs is becoming measurable and therefore optimizable. You can treat it like a novelty. Or you can treat it like day one of a race that ends with a new class of market leaders.
What is Generative Engine Optimization
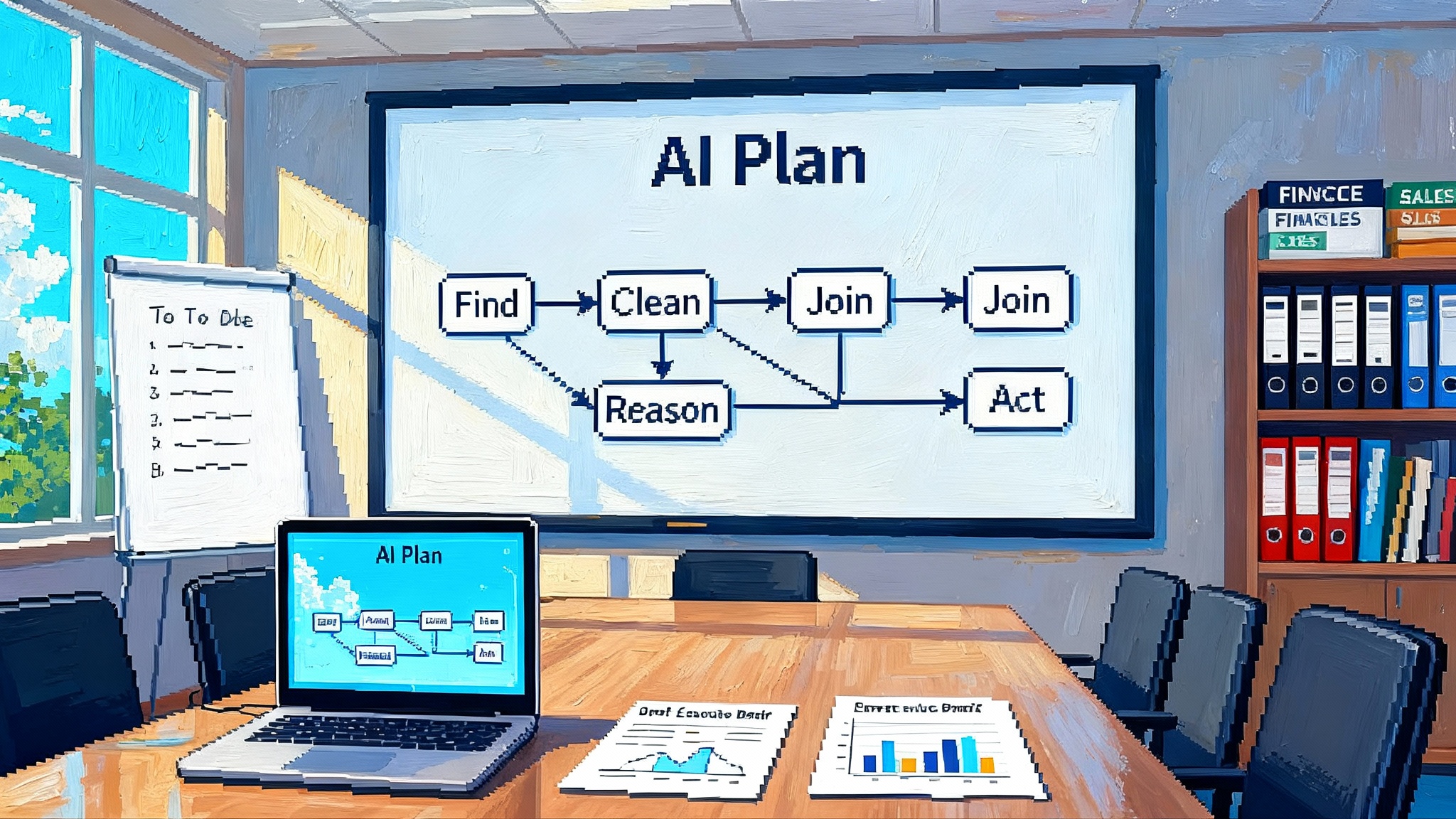
Generative Engine Optimization is the practice of winning visibility and action inside the answers produced by large language models. If search engine optimization was about ranking among pages, GEO is about being chosen for the synthesis. The unit of competition is no longer a page impression. It is a sentence, a citation, a tool call, or a structured snippet that moves the user forward.
Think of assistants as editors. They ingest the open web, your documentation, your product database, and your brand’s actions through tools. Then they decide who gets to be quoted, who gets to be called, and which source becomes the answer. GEO is the craft of making your brand the easiest and safest choice for that editor.
Why LLM placement becomes a primary growth channel
- Assistants compress choice. A page of links gives users optionality. An assistant gives a single, synthesized recommendation. That concentrates demand on the winners that are visible inside the answer.
- Friction trends toward zero. Users do not click three pages deep when the assistant can call a tool and complete the task. If your brand is not callable or citable, you are invisible at the moment of intent.
- Distribution follows defaults. Assistants are being embedded across operating systems, keyboards, browsers, and voice interfaces. The starting point of many user journeys will be an assistant. The brands that secure presence at this default surface will compound. Publishers are already adapting to answer-first products as seen in our piece on licensed AI search for publishers.
The implication is simple: the marketplace is tilting toward answer surfaces. GEO is how you earn a durable slice of those surfaces.
The accelerationist GEO playbook
You do not need a new religion. You need a focused operating system for the next four quarters. Use Sellm’s launch as your cue to move from theory to practice.
1) Measure answer share and citation coverage
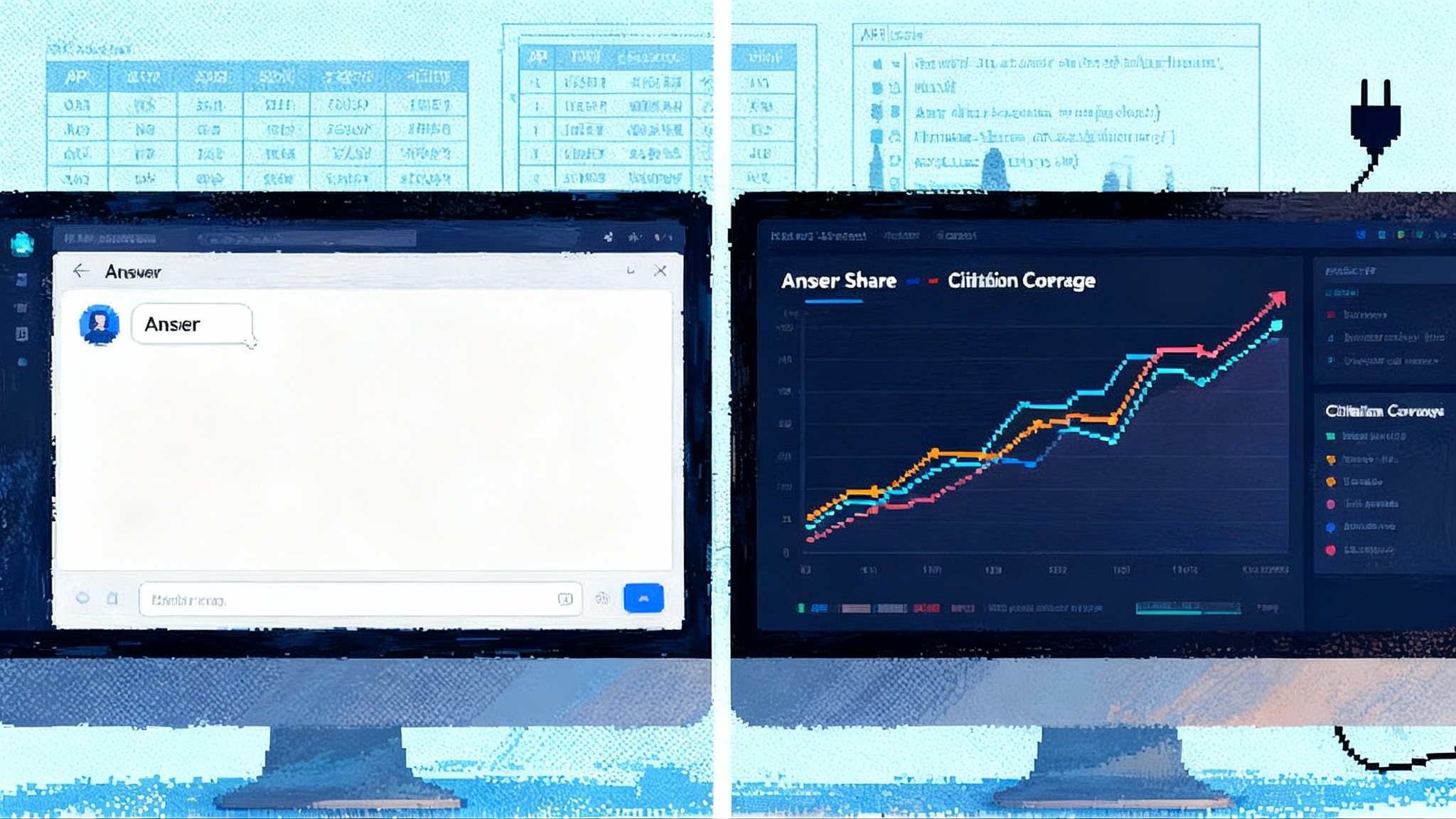
You cannot improve what you cannot see. Start with metrics that mirror the new funnel.
- Answer share. The percentage of assistant answers, for a defined question set, where your brand is present. Presence can mean named mention, quoted content, a citation, or a tool call. Segment by intent class: informational, comparative, transactional, and support.
- Citation coverage. The percentage of answers where the assistant cites one of your owned sources. Docs, blog, product catalog, pricing page, support articles, or your API documentation. Coverage indicates the assistant has found canonical, trusted material.
- Call inclusion. The percentage of answers where your tool, plugin, or app is eligible and selected for execution. This is the highest value placement because it closes the loop.
- Confidence delta. The change in the assistant’s expressed certainty when your source or tool is present versus absent. This is a proxy for usefulness.
How to measure without boiling the ocean:
- Build a question set. Start with 200 to 500 questions that matter for your category. Include head terms like best running shoes for flat feet and long tail prompts like waterproof trail shoes for winter under 150 dollars. Keep a simple taxonomy so every question rolls up to one intent class.
- Automate captures. Schedule daily runs that submit these questions to leading assistants and store the full answer text, citations, and any tool calls. Persist everything with timestamps, locales, and model versions so you can explain variance.
- Parse and score. Use extractors to detect your brand name, product names, and owned domains. Track position within the answer: first paragraph, bullet list, closing recommendation. Assign weights that reflect prominence.
- Trend it. Plot answer share and citation coverage weekly by intent class. Set targets. Tie incentives to movement. If you are moving beyond dashboard vanity and toward action, you will resonate with the argument in end of dashboard culture.
This turns assistants from a black box into a dashboard with dials that product and content teams can turn. When leadership asks if assistants matter, you can point to a graph.
2) Optimize structured data and APIs for retrieval
Assistants do not read your site the way a person does. They harvest structured facts, safety signals, and executable affordances. Treat your content and data as fuel for retrieval and synthesis.
- Canonical fact tables. Publish source of truth pages for pricing, features, dimensions, compatibility, inventory, and shipping. Use consistent identifiers and stable anchors so the same facts resolve across your site, docs, and catalog.
- Schema markup. Use widely recognized vocabularies for products, how to guides, reviews, and frequently asked questions. Keep markup fresh as you change content and inventory. Out of date structured data is worse than none.
- Machine readable catalogs. Provide feeds that mirror your key objects. Products, locations, services, menus, and schedules. Include currency, units, and geographies. Assistants reward clarity.
- Real time APIs. Expose a rate limited endpoint for availability, price, or appointment slots. If an assistant can call a fresh source during composition, your facts become the safest to use.
- Evidence and provenance. Add published dates, author names, version numbers, and last reviewed fields to important pages. Assistants rely on freshness and accountability signals to avoid outdated answers.
- Error semantics. Return precise error codes and guidance when data cannot be retrieved. LLMs handle explicit constraints better than silent failures.
Treat these like ranking factors. They are. When assistants can fetch current price, verify a claim, and show a verified badge from your domain, they will prefer you in synthesis.
3) Earn tool and agent inclusion
Being cited is good. Being callable is growth.
- Build an assistant facing tool. Identify one or two high intent actions that a user would be glad to complete without visiting your site. Book a demo. Check price and inventory. Generate a custom quote. Execute that as a simple, well documented tool with precise inputs and clear outputs. For a fast primer on conversion inside conversations, see chat to checkout is live.
- Design for reliability. Provide a health endpoint, predictable rate limits, and graceful fallbacks. Assistants favor tools that work every time.
- Ship a lightweight app. If the platform supports user installed apps or plugins, publish one that wraps your tool and showcases a few well crafted starter prompts. Keep the scope small and the value obvious.
- Create a brand safe prompt grammar. Provide examples that constrain the assistant to ask for the minimum inputs needed to perform a high value action. Less ambiguity means more inclusion.
- Prove user value. Track completion rates, user satisfaction, and time to task. Use these metrics in your store listing where applicable. Assistants will learn from user engagement signals.
The goal is straightforward: when the assistant considers which tool to call to satisfy the request, your brand should be the low risk, high clarity option.
4) Run continuous experiments to win the synthesis
The assistant is not a static index. It is a learning system that updates with new data, new prompts, and new tools. Treat GEO like a product program with weekly releases.
- Prompt and context tests. Run controlled prompts that vary the phrasing, context length, and intent specificity. Measure which variants increase answer share and citation coverage.
- Source ablation. Temporarily remove or add specific pages and measure how it changes your presence. This reveals which documents actually drive inclusion.
- Tool selection tuning. Adjust tool descriptions and schemas. Small edits to parameter names and output fields often change whether a tool is selected.
- Freshness cadence. Publish and update at a regular tempo. Assistants weight recency in many categories. A consistent beat can shift inclusion.
- Locale experiments. Localize content and data feeds. Many assistants prefer regionally relevant sources. Prove it with experiments.
Make it iterative, not ideological. The assistant will tell you what works if you instrument it well.
A GEO stack you can stand up in 90 days
Here is a practical architecture that a growth team and a platform team can assemble without waiting for a massive replatform.
- Inputs. A prioritized question set, a list of owned domains and subdomains, a catalog feed, a tools registry, and a prompt library.
- Capture. A scheduler that queries assistants, records answers, and stores raw outputs with metadata including model version, locale, and time.
- Parsing. Extractors that find brand mentions, citations, and tool calls. A lightweight classifier that tags each answer as informational, comparative, transactional, or support.
- Scoring. Modules that compute answer share, citation coverage, call inclusion, and confidence delta by segment.
- Surfacing. A dashboard that shows weekly trends, top gains and losses, and a diff view that highlights what changed in the answer.
- Action. A publishing pipeline that updates structured data, regenerates critical docs, and ships tool description tweaks each week.
- Guardrails. A review checklist for regulated claims, data retention, and consent. Growth should not outrun compliance.
If that looks familiar, it should. It resembles how mature teams run search engine optimization and conversion rate optimization. The novelty is the target surface and the tighter link between data quality and distribution.
Freshness, trust, and safety are the new ranking factors
Assistants play defense against hallucinations and harmful outputs. That raises the bar for the sources and tools they include.
- Fresh beats stale. When facts change fast, assistants look for current sources with explicit timestamps. Publish and update canonical sources rather than scattering facts across many posts.
- Provenance is not optional. Put authors, reviewers, and version history on important pages. Add contact paths for corrections. Make the assistant’s safety case easy.
- Constrained outputs win. Tools that declare strict parameter types, enums, and schemas are simpler to call. This increases selection in the moment of synthesis.
- Coverage matters. If you claim national service, ensure your location data and hours are complete for every region. Assistants avoid recommending brands with patchy coverage.
- First party verification helps. If you can verify ownership of domains, feeds, and tools within assistant ecosystems, do it. Verified sources are safer to include.
What success looks like by quarter
You can build momentum in four quarters without heroics. Treat this as a playbook you can hand to a cross functional team today.
- Quarter 1: Instrument measurement. Ship the capture system, define the question set, and publish canonical fact pages with schema. Baseline answer share and citation coverage. Socialize the metrics and set targets by intent.
- Quarter 2: Ship a callable tool. Wrap a single high value action. Optimize tool descriptions and add a few localized data feeds. Target a measurable lift in call inclusion and track completion rate.
- Quarter 3: Scale content and feeds. Expand machine readable catalogs, add regional coverage, and localize priority pages. Run prompt and source ablation experiments weekly. Start to correlate freshness cadence with inclusion lift.
- Quarter 4: Defend and compound. Harden reliability, improve latency, and formalize compliance. Expand to a second assistant ecosystem and measure cross platform lift. Tie tool calls to revenue attribution and budget accordingly.
By the end of the year, your brand should show steady gains in answer share for head and mid tail intents, rising citation coverage from owned sources, and a clear line from tool calls to revenue. That is a growth channel, not an experiment.
Common pitfalls that slow GEO efforts
- Chasing hallucinations. Do not optimize for edge case prompts that produce odd answers. Focus on intents that matter and fix the sources assistants should prefer.
- Over indexing on one assistant. Diversify across major ecosystems. Port your structured data and tools so you can measure lift in more than one place.
- Shipping a kitchen sink tool. Small, reliable tools are selected more often than sprawling ones. Narrow scope wins inclusion.
- Ignoring latency and rate limits. Assistants will skip slow or unreliable tools. Treat performance budgets as ranking factors.
- Neglecting legal and brand safety. Add governance with claim review, data retention rules, and user consent paths for any personalized actions.
A practical checklist to start this week
- Assemble a cross functional GEO pod with growth, content, developer experience, and legal.
- Define the first 300 questions across informational, comparative, transactional, and support intents.
- Baseline answer share, citation coverage, and call inclusion. Ship a dashboard.
- Publish canonical fact pages with timestamps, authors, and schema markup.
- Expose a small real time endpoint for a single high value fact. Inventory, price, or appointment slots.
- Draft and publish one assistant facing tool with tight inputs and clear outputs.
- Schedule weekly experiments: prompt variants, source ablations, and tool description tweaks.
- Set quarterly targets and tie incentives to measurable movement.
The moment before the arms race
When a scoreboard appears, the game begins. Sellm’s launch did not create Generative Engine Optimization. It revealed that the channel is ready for measurement and iteration. That is the threshold where winners separate from the pack. The brands that instrument early will discover which facts and tools move inclusion. They will publish cleaner data, earn more citations, and become the default choice inside the assistant’s answer.
By the time everyone else shows up with budgets and slogans, the early movers will own the habits that placement requires. There is nothing speculative about this shift. Assistants already shape decisions across research, shopping, travel, and support. The only open question is whether your brand will be present at the moment of synthesis. Start measuring, start publishing structured truth, start earning tool inclusion, and start testing. GEO is not a future trend. It is a channel you can grow today.