Publisher-owned AI search goes live with Gist Answers
ProRata.ai has launched Gist Answers, a publisher-owned AI search that cites sources, respects paywalls, and shares ad revenue. See what changes for SEO, traffic, and ads, plus a practical build guide to ship it right.

The moment AI search moved into the publisher’s house
On September 5, 2025, ProRata.ai turned a long-running argument into a working product. The company launched Gist Answers, an AI search experience that runs on a publisher’s own domain and pays that publisher when their work informs an answer. The launch arrived with a funding announcement and a clear signal to media operators: stop donating your best reporting to generic chatbots and start running an answer engine that carries your brand, your rules, and your economics. See the BusinessWire launch announcement for the formal details and the Axios coverage of the launch for early network numbers and revenue split.
Here is the essence. Gist Answers lets a publisher embed a custom search bar that returns answer cards generated from that publisher’s archive and, when enabled, from a vetted network of licensed sources. The system credits citations inside the answer, drives readers to the original articles, and splits revenue when ads run next to those answers. Taken together, this is the first credible alternative distribution channel to generic chat. It does not try to beat the general-purpose assistants. It gives publishers a way to keep their work inside their brand with licensing, attribution, and paywall-aware context baked into the product.
Why this is a real channel, not another widget
Most publisher widgets fail because they create a sidecar experience with no gravity. Gist Answers inverts that dynamic in three ways:
-
It sits on the publisher’s domain. That matters because trust and conversion are shaped by where the answer appears. When an answer renders inside a familiar template, the reader stays. Session depth increases. The odds of a newsletter signup or a subscription go up.
-
It treats content as licensed inventory. Instead of scraping, the system builds on consent, attribution, and clear rights. That sounds procedural, but it unlocks everything else: advertiser comfort, cross-publisher distribution, and predictable yield.
-
It bakes in monetization. The ad is not a banner parked under a paragraph. It is a native placement next to the answer card, sold on the intent that the answer itself reveals.
Think of the shift as moving from a flea market stall by the highway to a storefront on your own street. You keep the foot traffic you earn. When a neighboring store sends a customer your way, you both share in the sale.
What changes for SEO, traffic, and ads
Search engine optimization has long meant writing for crawlers and ranking on third-party pages. AI answers move the focus from blue links to direct responses. If those responses live on your domain, the incentives change again.
-
New SEO target: answer quality. The key metric is no longer a position on a search engine results page. It is whether your answer card is the best response to the reader’s question. Optimizing for this looks like improving retrieval coverage, tuning re-ranking for relevance, and grounding with precise citations. Editorial teams will tune the prompts and answer templates that control how the model quotes, summarizes, and links back into the archive.
-
New traffic pattern: answer to depth. Expect fewer bounces from shallow queries and more multi-card sessions. When answers act like a guided path, readers click into source articles for detail, then save or share those sources.
-
New ad economics: intent-rich inventory. When an answer states a fact, compares options, or outlines steps, it declares intent. Ads next to that intent command premium pricing. If the network splits revenue equally, every licensed contribution can become a yield event across partners.
-
New measurement: citation share. In a world of composed answers, an article’s impact is the number of answers it helps power multiplied by how often readers click through the citation. That is a sharper proxy for influence than raw pageviews.
These shifts mirror what we have seen as agentic systems become production-grade in other verticals. For instance, when we examined agentic AI in customer service, the most valuable metric moved from raw contact volume to successful autonomous resolutions. The parallel in publishing is clear: measure answer quality and citation engagement, not clicks to external result pages.
The technical shape of publisher-owned answers
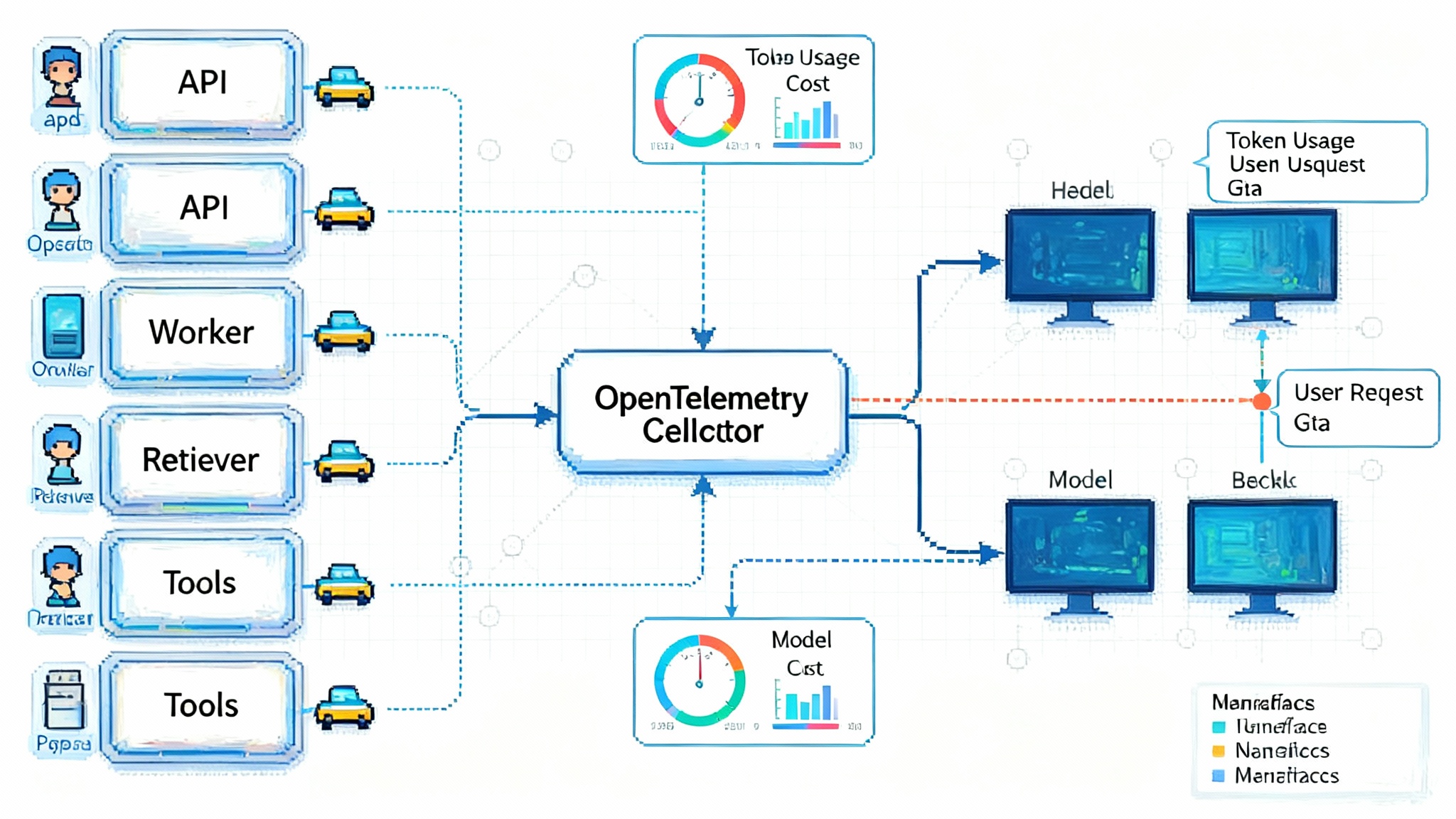
Under the hood, Gist Answers and similar systems follow a common pattern: Retrieval Augmented Generation, often shortened to RAG. Here is the shape that matters to product and platform teams.
-
On-site retrieval. Your archive is chunked into passages with stable IDs and rich metadata: canonical URL, publish date, author, topics, and policy flags. Those passages are indexed in a vector store for semantic search, plus an inverted index for high-precision keyword recall. A cross-encoder re-ranker promotes the most relevant passages to the top.
-
Content APIs and paywall awareness. A content API gates access according to a user’s status. If a reader is logged in, the system can ground answers on subscriber-only content. If not, it can draw from public passages or use summary-only transforms of paywalled text. The answer card can indicate that deeper details require a subscription and link directly to the source page.
-
Answer composition and citations. The model is forced to cite specific passages. Each sentence in the answer maps back to a passage ID. The renderer shows compact citations that link to full articles. This is ethical and practical. When an answer goes wrong, you can trace the source in seconds.
-
Evals you can live with. Build a golden set of questions that represent your coverage. Score retrieval precision and recall, citation correctness, and answer helpfulness. Pair automated checks with editor ratings. Treat these like unit tests and run them on every index update and model change. If you need to instrument this quickly, our guide to zero code LLM observability outlines a path to plug telemetry into your answer stack.
-
Safety and rights. Redact sensitive personal information at retrieval time. Honor embargoes and takedown requests by removing or re-flagging passages. Keep a policy layer that blocks answers in restricted topics unless grounding meets a higher bar.
-
Performance. Readers feel latency more in answers than in search pages. Aim for a sub-second retrieve and re-rank, then stream generated text to reduce perceived wait. Cache frequent questions as templated answers with fresh citations for speed and traceability.
Why an answers network is likely to form quickly
Networks grow when each participant gains more value as others join. Publisher-owned answers have several reinforcing loops.
-
Supply loop. Each new publisher adds licensed passages. Coverage expands, niche questions are answerable, and user satisfaction rises. That drives more usage across all sites running the experience.
-
Demand loop. As intent-rich answers cluster, advertisers follow. Native placements next to grounded claims outperform generic banners. Better performance lifts yield, which attracts more publishers to license content into the network.
-
Quality loop. Editors across the network push improvements into shared retrieval and evaluation tools. When the re-ranker improves, every partner benefits.
-
Distribution loop. A reader finds an answer on Publisher A that cites Publisher B. The reader clicks to B, which then keeps that reader in its own answer experience. This is cross-pollination without losing brand control.
The deeper effect is that circulation no longer depends entirely on a single external algorithm. Answers become a first-class distribution surface that publishers control, improve, and monetize together.
The economic implications in practice
-
Pricing power returns to context. When you sell an ad next to a grounded answer about retirement accounts, camera buying guides, or home energy upgrades, you can price against declared intent. That turns a passive pageview into an active lead.
-
Rev share changes rights bargaining. A library contribution that powers answers across many sites becomes a financial asset. Archives with depth and authority gain a second life as answer inventory. Smaller publishers can gain reach and revenue by contributing specialized expertise to the network.
-
Better fit for subscription funnels. Paywall-aware answers can tease insight while keeping full value behind the login. You stop forcing readers to choose between zero access and total leakage.
-
New editorial craft. Writers will craft pieces that chunk into reusable passages. Editors will define the questions each story should be able to answer. Analytics teams will watch which passages earn the most citation clicks and commission updates accordingly.
These dynamics echo what we have seen as agents move off the demo bench and into real workflows. Our coverage of vertical MCP interoperability explores how standards concentrate value where control and trust already exist. The same logic applies here. Standards for answer cards will concentrate value with publishers who already own audience relationships and archives.
Build guide: plug your archive into AI without surrendering control
Here is a practical blueprint for teams who want to move fast while keeping their rights intact.
-
Set the objective. Choose one primary outcome for the first 90 days. Reduce bounce on evergreen pages, drive newsletter signups from answers, or increase subscription conversion on topic hubs. A single target clarifies choices.
-
Inventory your content and rights. Audit which sections are public, meter-controlled, or fully paywalled. Map third-party rights, photo licenses, and embargo rules. Build a simple policy table that associates each article with a license status and allowed transformations.
-
Create a clean content API. Expose endpoints that return article text, metadata, and access flags. Include canonical URL, update timestamp, author, topics, section, and legal flags. Add a signed-token path for subscriber-only content so your answer engine can ground responsibly.
-
Prepare the index. Chunk articles into passages of 300 to 500 tokens with a 50 to 100 token overlap to preserve context. Store a stable passage ID that includes the article ID and paragraph offsets. Generate embeddings with a high-quality multilingual model if you publish internationally. Keep an inverted index in parallel for exact terms and names.
-
Add a re-ranker. Use a cross-encoder to re-rank the top 200 retrieved passages down to the final 10 to 20. This step improves answer quality more than almost any other because it reduces off-topic grounding.
-
Compose answers with strict grounding. Force the model to cite by passage ID for every claim. Include a rule that any sentence without a citation is dropped or rewritten. Render citations as compact badges that link to full articles. Let readers expand the source snippet to see the exact supporting text.
-
Make it paywall aware. If a top passage is subscriber-only, present a summary plus a clear call to log in or subscribe. Offer a free preview threshold so answers still feel helpful. Never leak full paywalled text into the answer. The model should only quote from public or licensed-to-display snippets.
-
Place monetization next to intent. Design a single native ad slot in the answer card. Bind targeting to detected intent categories and entities. Cap frequency and guarantee brand safety by filtering against your policy tags. Start with a fixed sponsorship to prove value, then migrate to dynamic pricing.
-
Build evaluations you trust. Create a golden set of 300 questions across key beats. For each, store the ideal citations and an editorially approved answer. Score your system weekly for retrieval accuracy, citation correctness, and user-rated helpfulness. Add latency and time-to-first-token as service level indicators.
-
Ship guardrails. Redact personal information detected by your named-entity recognizer at retrieval time. Block hallucination hot spots by disallowing answers in topics where you lack strong sources. Give editors an override panel to pin or blacklist sources for specific queries.
-
Wire analytics to actions. Track answer impressions, citation clicks by source, assisted conversions, and revenue per thousand answer impressions. Tie metrics back to passage IDs so you can promote and update content that earns citations.
-
Pilot cross-licensing with neighbors. Start with two or three trusted publishers in adjacent beats. Swap a subset of passages, define shared categories, and agree on a simple revenue split. Use the pilot to pressure-test your policy table, paywall logic, and attribution display.
-
Announce your answer policy to readers. Tell your audience how answers are built, how sources are credited, and how advertising works. Transparency earns trust and reduces confusion when readers encounter a new format.
What to watch next
-
Standardization of answer metadata. Expect a simple schema for answer cards, with fields for passage IDs, citation URLs, model version, and policy flags. Shared formats will make cross-site distribution easier and safer.
-
Emergent answer marketplaces. As a handful of publishers run compatible answer formats, trade groups and media networks will stitch them into larger exchanges. That lets an advertiser buy answers across categories while keeping attribution tight.
-
Editorial controls as a product wedge. The systems that give editors fine-grained control over prompts, tone, and fallback behavior will win adoption. Editors will insist on being able to pin a house style and a house canon.
-
Answer-first site design. Topic pages and evergreen guides will elevate answer cards at the top, followed by curated reading paths. The article becomes the primary citation object feeding the answer above it.
Bottom line
Generic chat pulls value away from the people who make the knowledge. Publisher-owned AI search pulls it back. Gist Answers proves the model in the wild: licensed retrieval, visible attribution, and a straightforward revenue share that rewards the sources. If you run a newsroom or a specialist publication, this is the moment to plug your archive into an answer engine you control. The playbook is clear. Build with strict grounding and visible citations. Keep paywalls honest. Put a single ad next to declared intent. Measure what matters. Grow the network with neighbors you trust.
Do this well and the next era of search will not happen to you. It will happen on your site, with your bylines, and your economics.